학습목표
a. Text2Image는 무엇인가? KSampler는 무엇인가?
b. 모델이란 무엇인가? 체크포인트? 로라?
Plain Text
복사
워크플로우
인덱스 | 워크플로우 이름 | 실행가능한 링크 | 요약 |
4.1.1 | Text2Image(SDXL) | SDXL일때 Basic Generation | |
4.1.2 | Text2Image(SD1.5) | SD1.5일때 Basic Generation | |
4.1.3 | Text2Image + LoRA | SDXL일때 LoRA를 함께 쓰는 방법 | |
4.1.4 | Text2Image + Multi LoRA | SDXL일때 LoRA를 2개 겹쳐쓰는 방법 | |
4.1.5 | Text2Image + Checkpoint Merge | 2개의 SDXL 체크포인트를 병합해서 쓰는 방법 | |
4.1.6 | Image2Image(SDXL) | SDXL T2I에 Load Latent Image를 추가한 I2I |
a. Text2Image는 무엇인가?
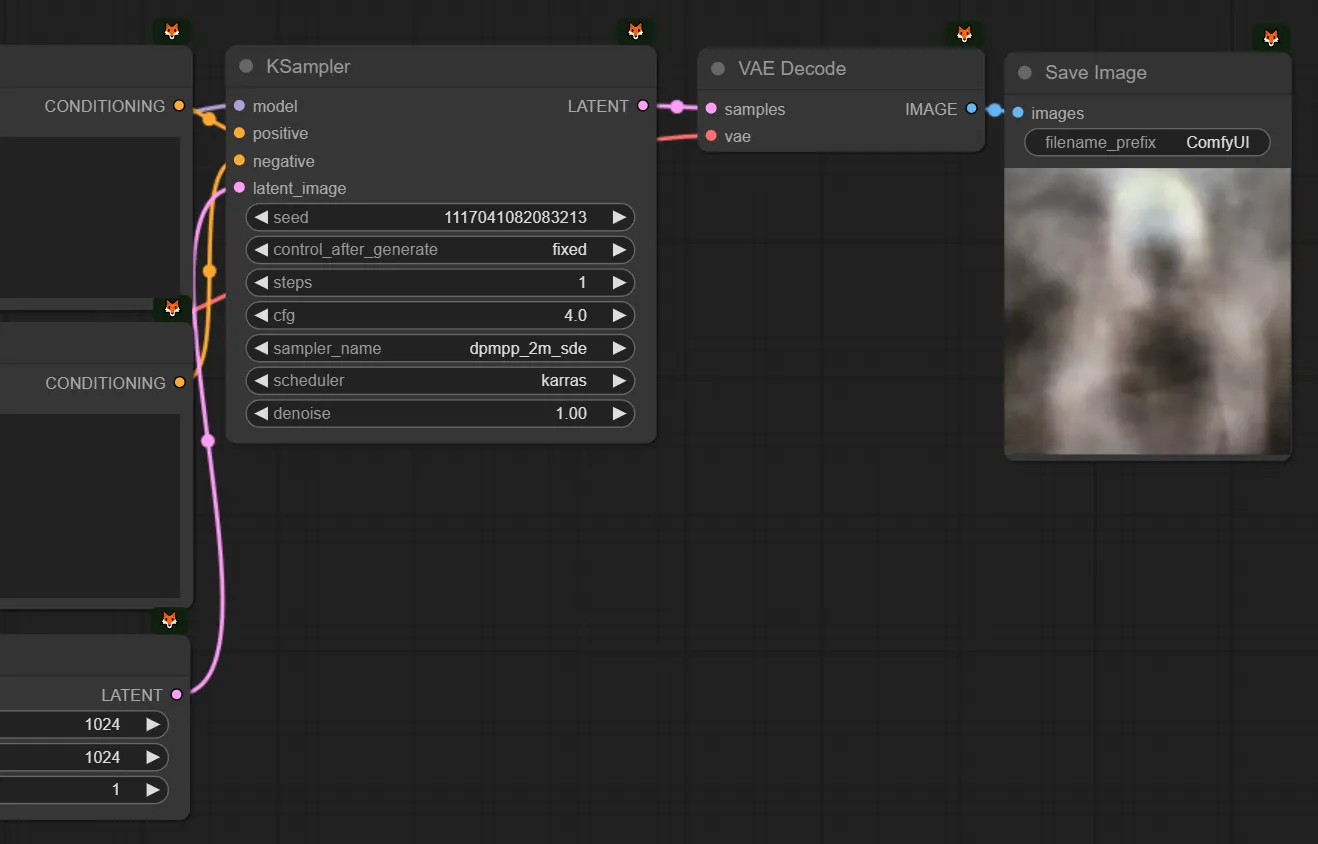
우선 이 그림을 잠시 째려보면서, 그림과 개념을 연결시켜가면서 보시면 좋을 것 같습니다.
심화적인 이해를 할 수 있도록 개념화시킬 수 있도록 하겠습니다. 색은 구분이 잘 가지 않지만 Comfy의 기본 색상을 따랐습니다.
.png&blockId=ed86a07e-cfff-4d11-b068-0fcc86d68a43)
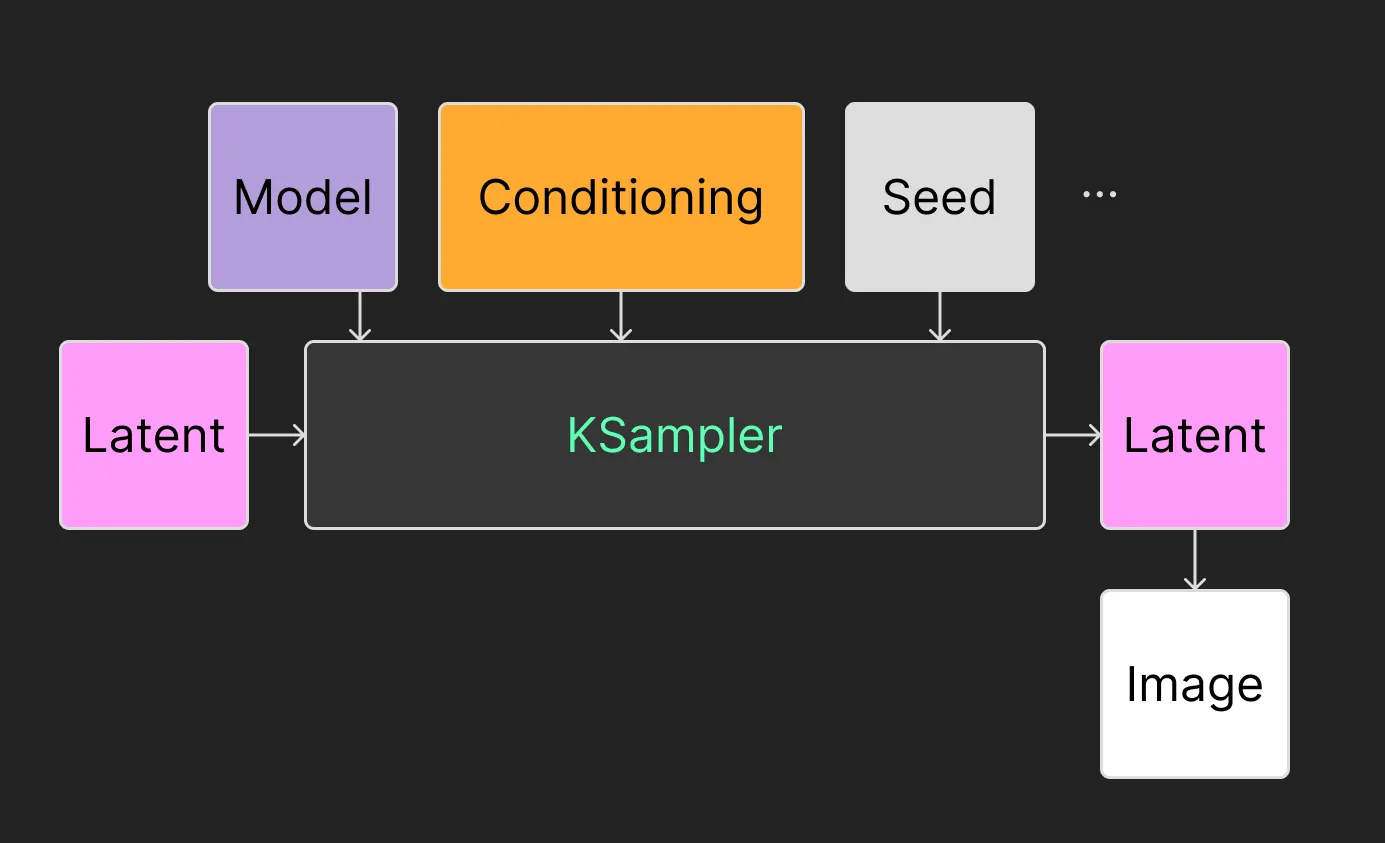
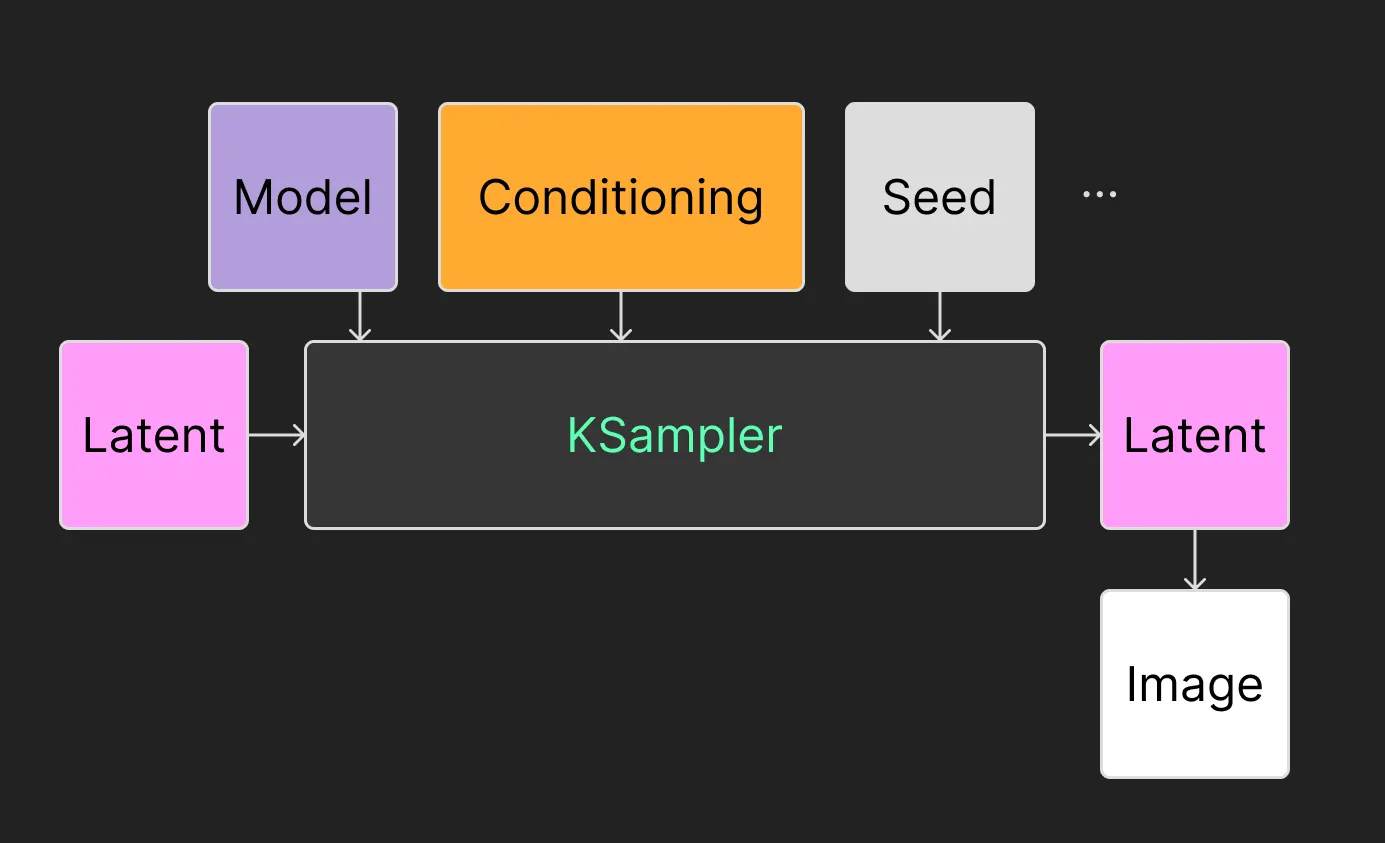
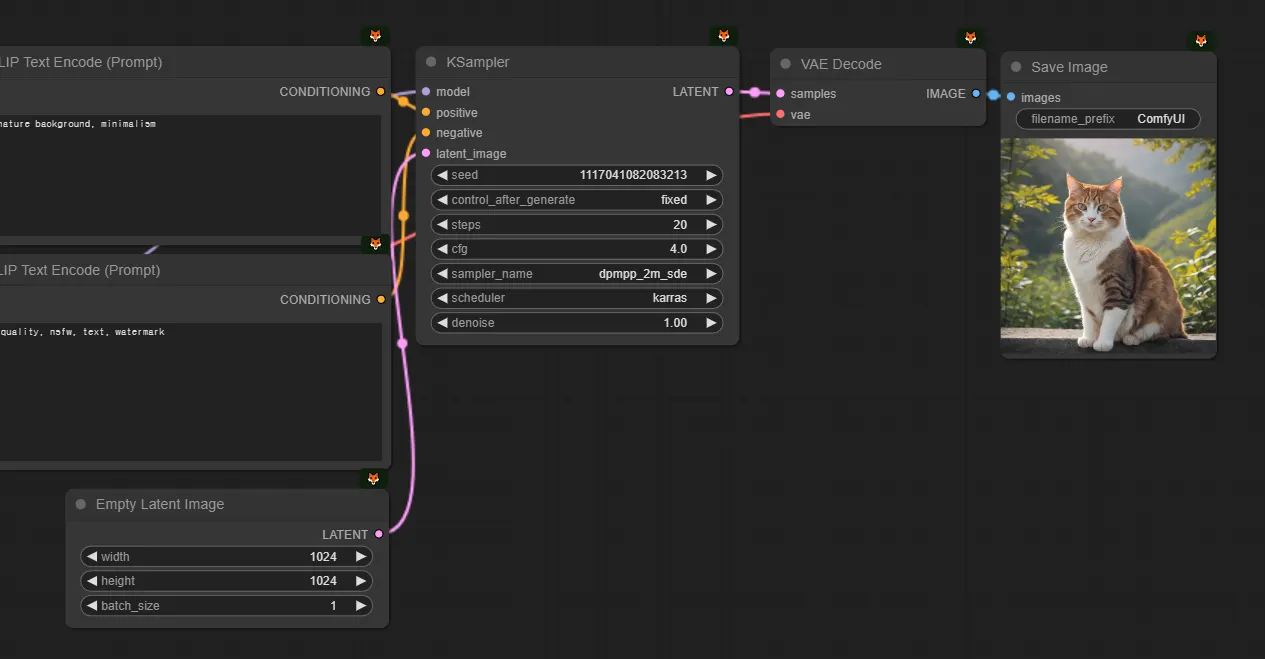
Seed & Latent
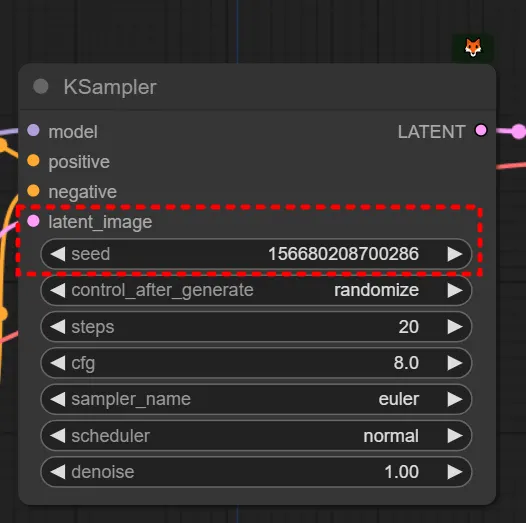
text image에서는 Latent로 Empty latent image를 넣어줍니다. (768x1024 비율을 갖는 이미지라고 해봅시다.) 그리고 KSampler에서는 seed값을 설정합니다. 그 말은, 입력으로 이런 노이즈를 넣겠다는 뜻입니다. (실제로 이렇게 생기지는 않았습니다.)

Conditioning
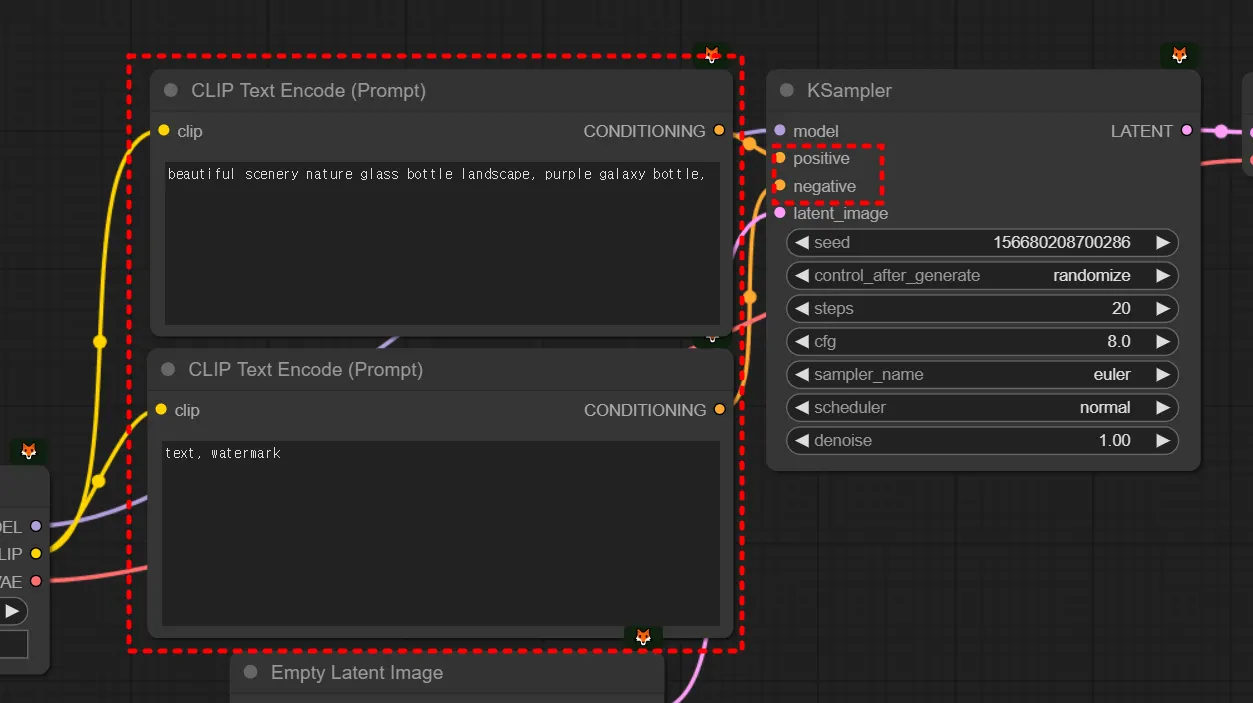
어려운 단어지만 쫄지 맙시다. condition이라는 단어는 ‘조건’이라는 뜻입니다. 즉 무작위로 생성하지 않고, 내가 입력한 프롬프트대로 만드라는, 조건을 넣어주는 것입니다. 즉 프롬프트는 사실 컨디셔닝의 한 종류입니다. 뒤에서 컨트롤넷에서도 컨디셔닝을 넣어줄 수 있습니다.
KSampler
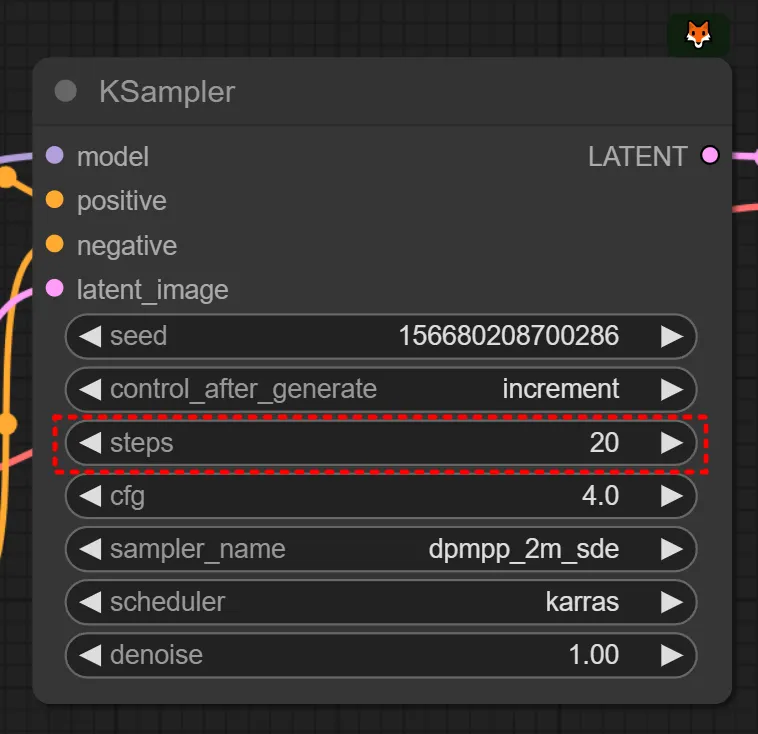
만약 제가 ‘1girl’이라고 프롬프트를 입력했다(=컨디셔닝을 걸어줬다)고 칩시다. 앞서 설명했듯 step = 20 로 하고, 다른 설정값들이 설정되어있다고 치면 노이즈로부터 20번 디노이징/샘플링을 하면서 이미지를 만든다고 볼 수 있습니다.
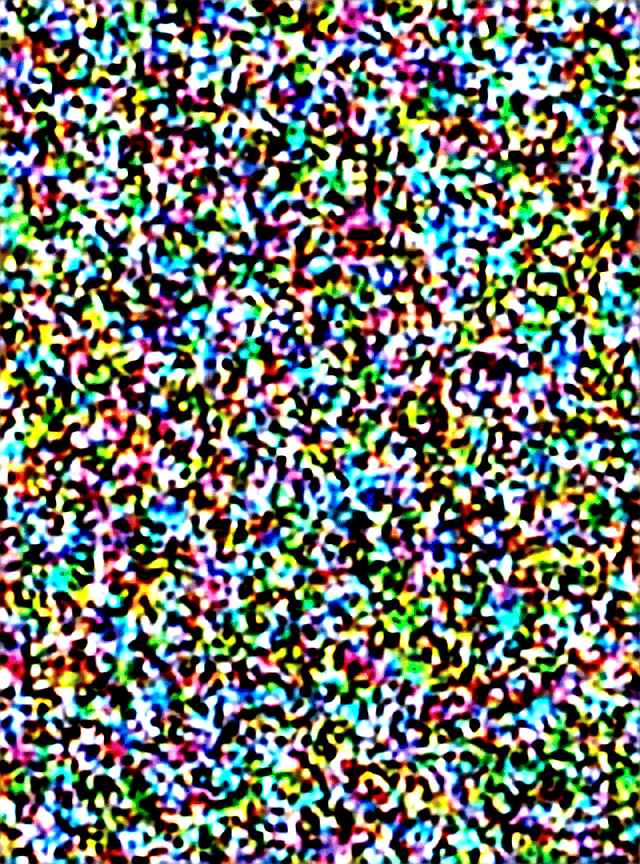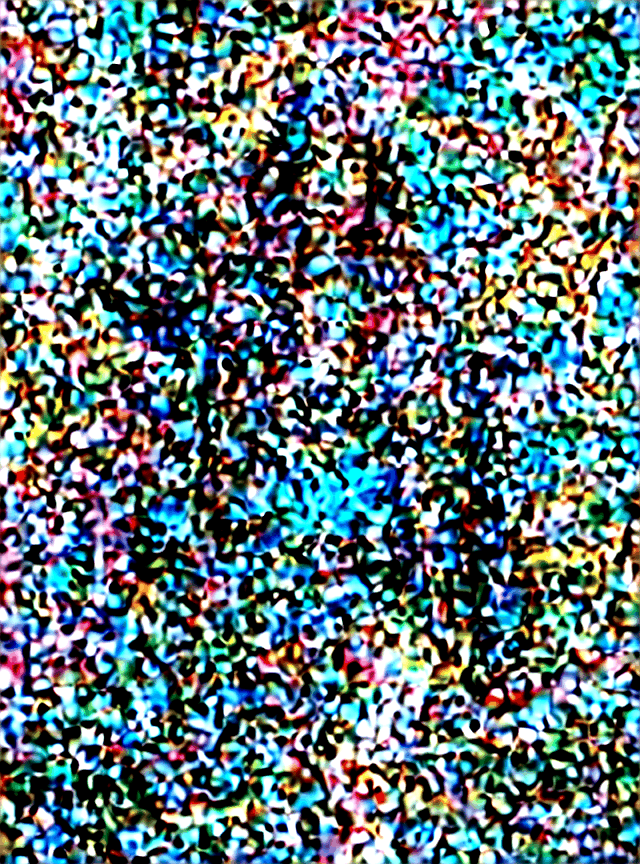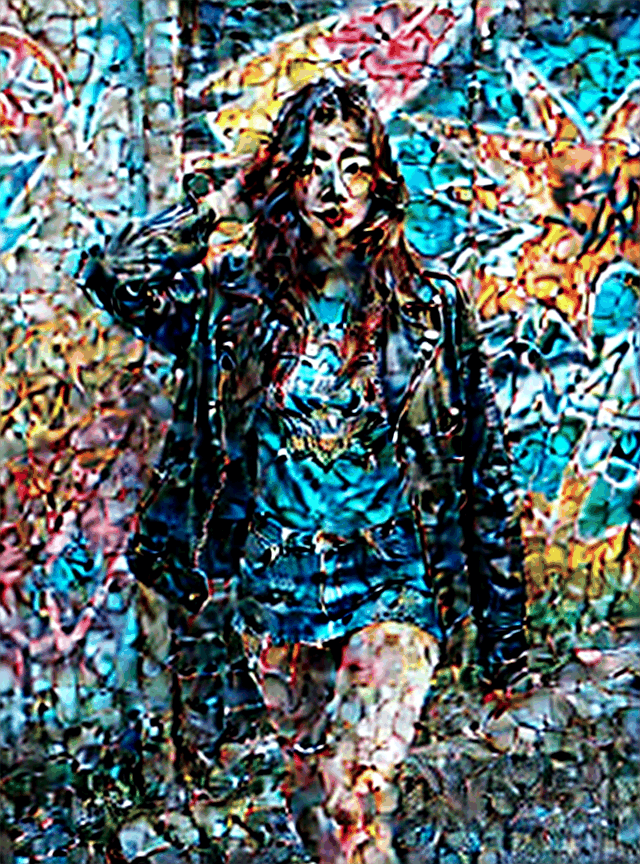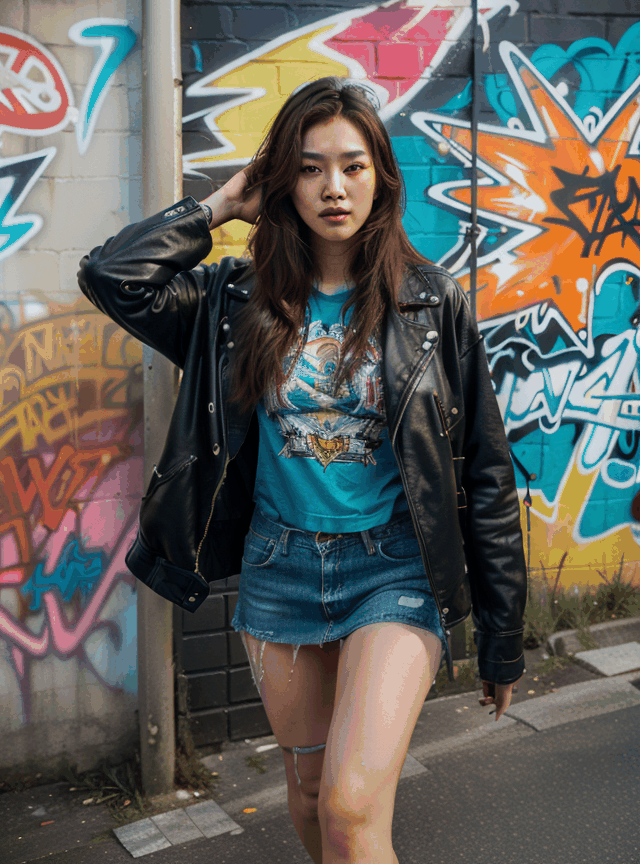
즉 스테이블디퓨전은 KSampler가 초기 시드 노이즈로부터 디노이징을 해나가는 과정입니다.
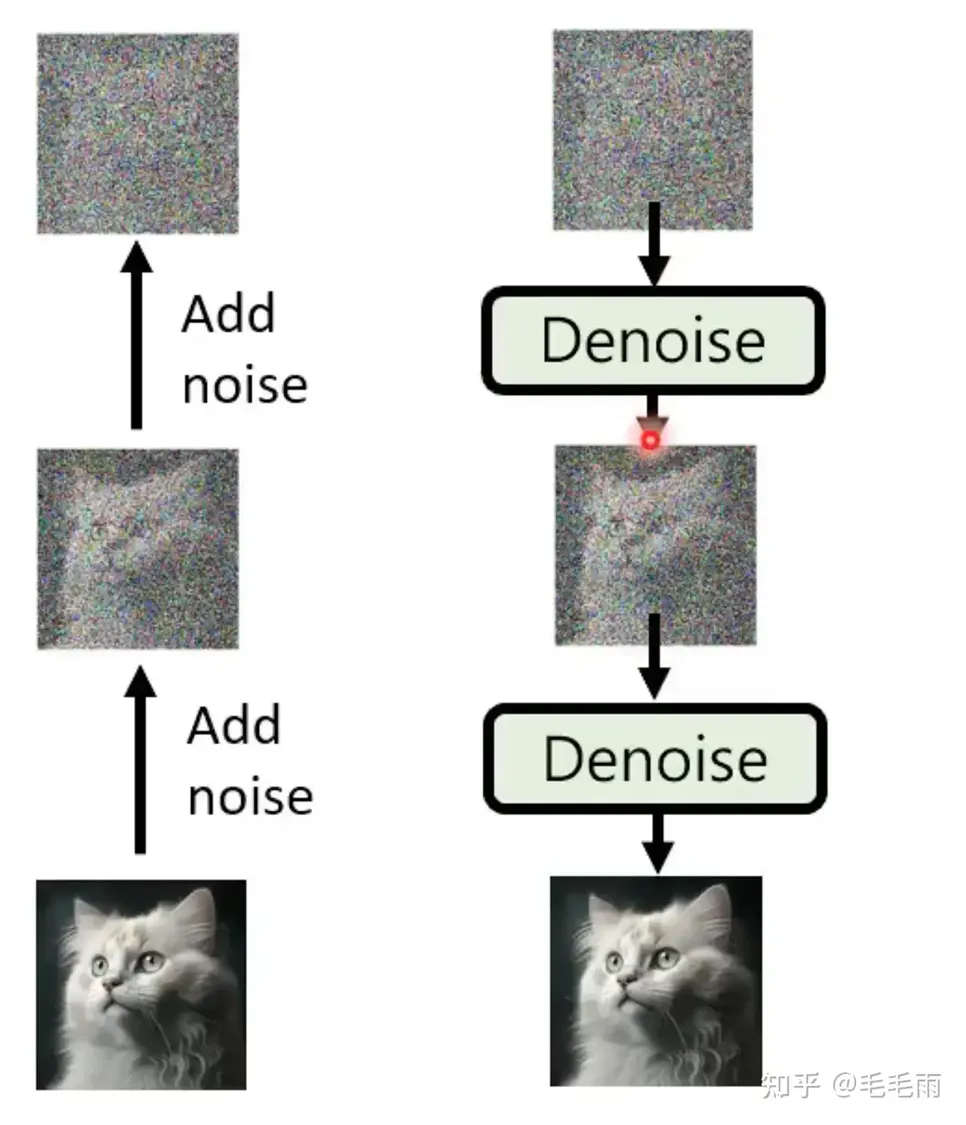
그래서 step을 매우 적게 걸면 이렇게 좋지 않은 이미지가 나오는 것을 볼 수 있습니다. 그렇다고 해서 필요한 범위 (ex.20)를 넘어선다고 해서 더 좋은 이미지가 나오는 것은 아닙니다. (하지만 특수한 모델들의 경우에 step을 60으로 요구하거나 하는 케이스도 존재하기는 하나 소수입니다. 그와 역으로 LCM 같은 경량화 모델을은 낮은 step을 요구로 합니다.)
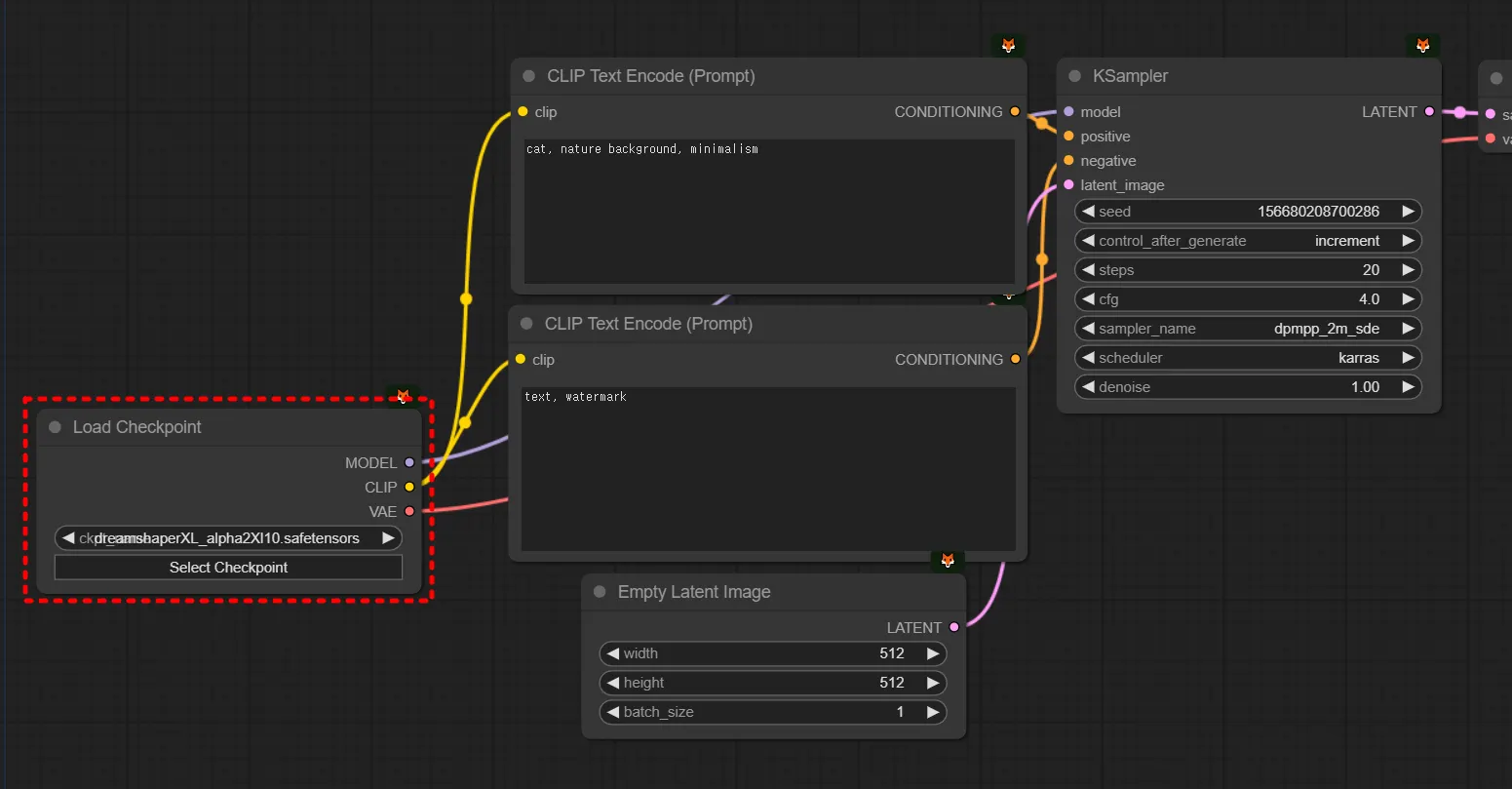
b. 모델이란 무엇인가? 체크포인트? 로라?
인공지능은 다양한 ‘인공지능 모델’이 존재합니다.
그 중에서 디퓨전을 활용한 스테이블디퓨전 모델들을 체크포인트라고 부릅니다.
체크포인트
게임을 하다보면 내가 어느 레벨까지 왔는지 저장하는 기능이 체크포인트라는 이름으로 존재합니다. 예를들자면 레벨35때 통나무 아이템을 7개 획득한 순간을 임시저장 하는 것이죠. 나중에 이 시점으로 언제든지 다시 돌아올 수 있습니다. 이와 유사하게 학습을 하다가 어느 순간의 값을 캡쳐하듯이 저장해두는 유사한 개념입니다. 그래서 파일의 확장자는 ckpt이지만 조금 더 보안적으로 안전하도록 safetensor를 사용합니다.
모델을 이해하기 위해서는 ‘트레이닝’ 즉 학습 과정을 이해하는 것이 도움이 됩니다. 저희가 지금 쓰는 모델들은 어떻게 탄생했을까요?
열심히 연구를 하시며 논문을 작성하시는 Researcher 또는 그러한 수준의 수학적인 것들을 이해하시는 Engineer 들이 SDXL, SD1.5의 베이스 모델을 만들어둡니다. 그러한 베이스모델은, 엄밀히는 아니고 대략적인 감을 잡자면, GPU 100개로 이미지 수천만장을 몇주에 걸쳐 계속 학습을 시켜두었다고 생각하시면 됩니다. (이것을 Train From Scratch 라고 하기도 합니다. 아예 아무것도 없는 것에서 학습을 시작한 것입니다.) 그리고 저희가 쓰는 모델은 그 베이스모델을 기준으로 해서 몇천장 또는 몇만장 (또는 그 이상)을 학습시켜둔 것입니다. (이것을 Train From Base 라고 하기도 합니다. 특정 베이스모델을 기준으로 해서 학습을 시킨 것입니다.)
그럼, 이렇게 학습을 시키면 어떤 일이 일어날까요? 엄청 대단한 일이 일어나는 것이 아닙니다. 쉽습니다. 이것을 이해하세요.
그냥 숫자덩어리가 업데이트될 뿐입니다. 저희가 알고있는 체크포인트는 대단한 것이 아니라 [0.3, 0.25, 0.87, 0.9, 0.5, 0.23, …] 이런 단순한 ‘숫자뭉치’ 즉 ‘배열’일 뿐입니다. 여기에 조금 더 학습을 시킨다? 그럼 0.3 → 0.25, 0.25 → 0.27, … 이런식으로 수정된 배열이 나오는 것 뿐입니다. 즉 모델은 그냥 특정 데이터에 최적화되어 학습된 그냥 숫자 뭉치일 뿐입니다. (현재 저희는 엄밀한 이해를 하는 것이 아닌, 저희가 응용해서 써먹기 좋은 수준의 이해까지만 하는 중입니다!)
그래서, 애니메이션을 잔뜩 넣고 학습시킨 체크포인트는 애니메이션을 잘 뽑고, 사진을 잔뜩 넣고 학습시킨 체크포인트는 실사를 잘 뽑습니다. 또는 3d 유니티/언리얼 사진만 잔뜩 넣고 학습시킨 체크포인트는 3d와 유사한 질감을 가진 스타일을 잘 뽑아줍니다.
로라
그럼 로라는 무엇이냐?
체크포인트의 용량은 6GB, 7GB, … 용량이 매우 큽니다. 저장해야할 숫자들이 기하급수적으로 많다보니, 그래서 용량이 많이 나갑니다. 학습하는 과정에서 엄청 여러개의 모델이 나오는데, 그럼 간단한 데이터 몇장 학습시키려고 할때마다 60GB, 70GB 이상을 사용해야 합니다. 불편합니다. 그래서 이것을 경량화하기 위해서, LoRA라는 기술이 LLM(거대언어모델) 영역에도 열심히 연구가 이루어지고 있었습니다.
그런데, 여러 사람들이 실험하다보니, 전체 체크포인트 중에서 딱 1% 정도의 가중치만 조절해줘도, 어느정도 체크포인트랑 비슷한 효과가 나는 겁니다. 그래서, 데이터 30장~100장 정도만 가볍게 학습시켜서, 체크포인트와 결합해서 쓰는 로라 방식도 꽤나 대중화되어 자리를 잡게 되었습니다. 즉, 체크포인트의 1% 정도 용량에 해당하는 경량화된 모델이라고 이해하셔도 좋습니다. 체크포인트가 더 좋은거 아니냐? 생각보다 체크포인트 만큼 강력합니다.
또한, 체크포인트가 [0.3, 0.25, 0.87, 0.9, 0.5, 0.23, …] 이라면 로라는 체크포인트가 학습하면서 변화한 량인 [0.003, -0.0025, 0.008, -0.009, 0.005, -0.0023, …] 를 저장합니다. 그래서 로라는 단독으로는 쓰지 못하고 체크포인트와 조합해서 쓰여야합니다.
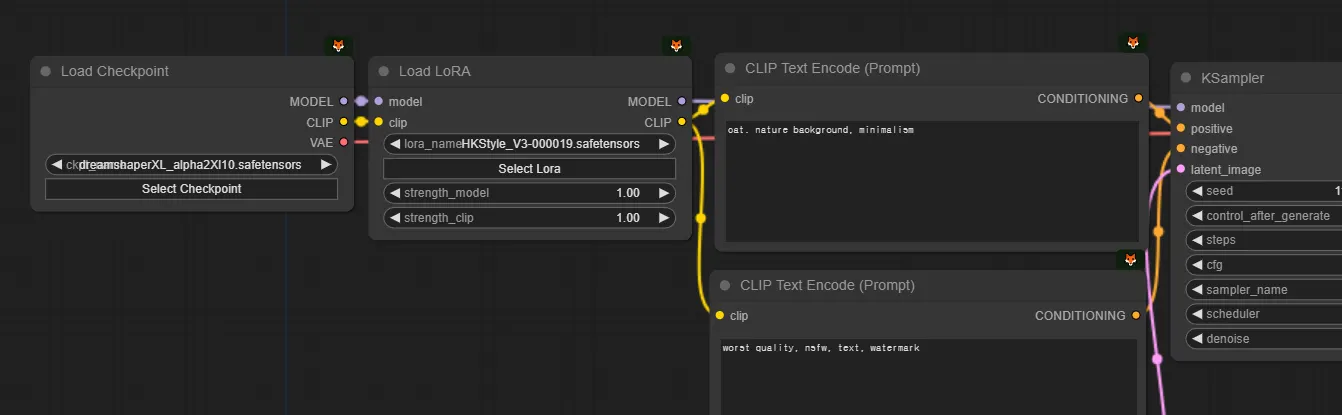
위 그림은 체크포인트와 로라를 연결한 모습인데 model, lora_name, strength_model을 주목해주세요. 이 값들이 아래와 같다고 합시다.
model: [0.3, 0.25, 0.87, 0.9, 0.5, 0.23, …]
lora: [0.003, 0.0025, 0.0087, 0.009, 0.005, 0.0023, …] # lora_name으로 읽은 로라 데이터
strength_model: 1
Python
복사
그러면 Load LoRA가 만들어내는 MODEL은 아래와 같이 계산되서 [0.3003, 0.2525, 0.8787, 0.909, 0.505, 0.2323, ...] 가 됩니다.
MODEL = inputModel + strength_model * lora
# MODEL: [0.303, 0.2525, 0.8787, 0.909, 0.505, 0.2323, ...] = [0.3, 0.25, 0.87, 0.9, 0.5, 0.23, …] + 1 * [0.003, 0.0025, 0.0087, 0.009, 0.005, 0.0023, …]
Python
복사
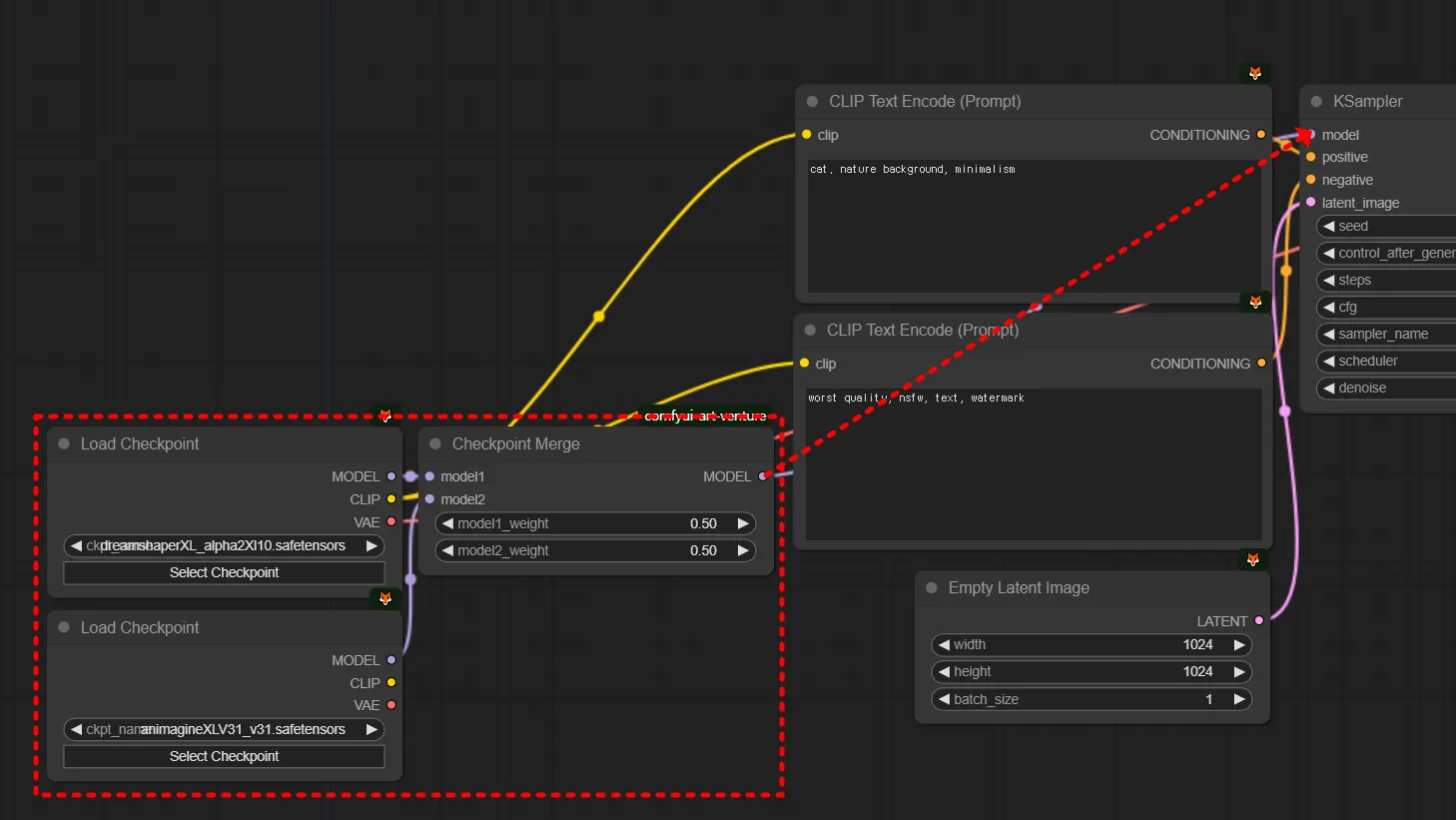
체크포인트 병합
애니메이션을 잔뜩 학습시킨 A 체크포인트와, 사진을 잔뜩 학습시킨 B 체크포인트가 있습니다. 반실사를 잘 뽑아주는 모델을 만들기 위해서는, 어떻게 해야할까요? 물론 A 체크포인트를 학습한 이미지와, B 체크포인트를 학습한 이미지를, 다시 모아서, 다시 학습시키는 것도 방법이 될 수 있고 그것이 아닌 반실사 이미지를 잔뜩 모아서 다시 학습을 시킬 수도 있습니다. 원하는 이미지를 모아야 원하는 이미지를 잘 뽑는 모델이 되겠지요.
그런데 신기한 일이 있었습니다. 이 지점을 잘 이해해보시면 좋습니다. 그냥 두 모델을 합쳤더니, 그 두 스타일이 합쳐지는 겁니다! 왜냐고요? 연구원들도 잘 모릅니다. ‘오… 이게 되네?’의 영역입니다. 정말로요.
어떻게 합치냐고요? 그냥 산술평균한 것입니다. 그냥 더해서 나누기 2 했다는 겁니다.
A 체크포인트 = [1, 0.8, 0.6, … ,0.8]
B 체크포인트 = [0, 0.4, 0.6, … ,0]
A+B 체크포인트 = [0.5, 0.6, 0.6, …, 0.4] # (A+B)/2
A의 첫 원소 = 1, B의 첫 원소 = 0, A와B의 평균 = (1+0)/2
Plain Text
복사
그냥 이렇게 하니깐 되네? 오 진짜 스타일도 합쳐지네? 해서 쓰고있는 겁니다. (이해를 위해 알려드리는 것이고 Checkpoint Merge가 아주 유용하다는 것은 아닙니다. 또한 연결시 붙어있는 Clip과 Vae는 그것을 알고 제대로 사용하고자 하는 것이 아니라면 어느 것을 쓰셔도 무방합니다.)
로라 겹쳐쓰기
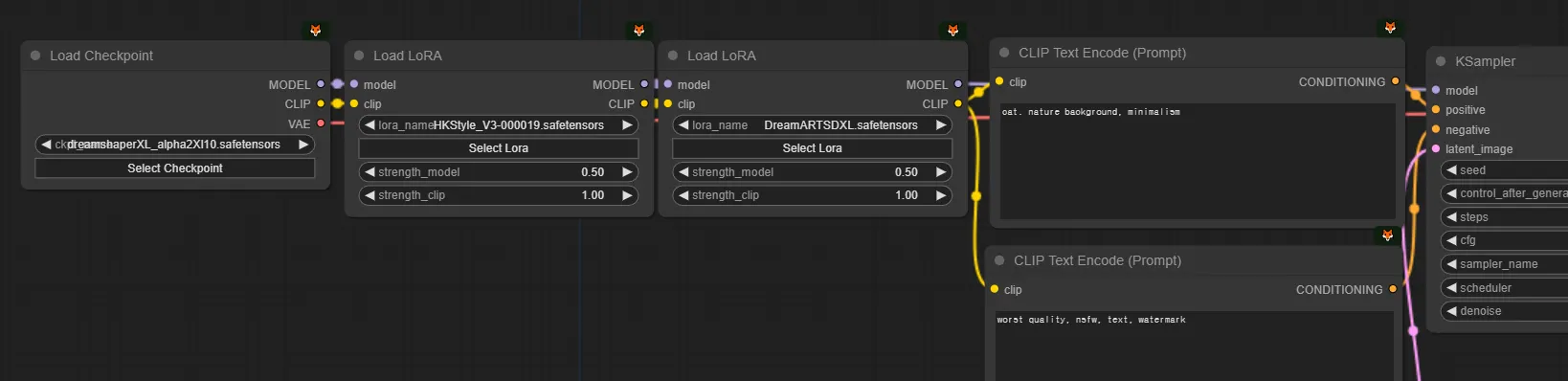
체크포인트 두개를 평균내는게 가능하듯이 체크포인트 하나에 로라를 여러개 겹쳐쓸 수 있습니다. 위 그림에서 캡쳐된 체크포인트(dreamsahperXL_alpha2Xl10), 로라1(HKStyle_V3-00019), 로라2(DreamARTSDXL)가 아래 데이터라고 예를 들겠습니다.
체크포인트: [1, 0.8, 0.6, … ,0.8]
A로라: [0.001, 0.008, 0.006, ..., 0.008]
B로라: [0.002, 0.016, 0.012, ..., 0.016]
Python
복사
그러면 Load LoRA를 두번 사용해서 만들어진 MODEL은 아래처럼 계산되고 두 스타일을 반반 섞은 효과가 납니다.
MODEL = 체크포인트 + 0.5*로라1 + 0.5*로라2 # 로라1, 로라2 앞에 0.5는 위 그림에 있는 Load LoRA에 있는 strength_model 값입니다
# MODEL: [1.0015, 0.812, 0.609, ..., 0.812] = [1, 0.8, 0.6, … ,0.8] + 0.5*[0.001, 0.008, 0.006, ..., 0.008] + 0.5*[0.002, 0.016, 0.012, ..., 0.016]
Python
복사
다시 말하지만, 체크포인트 병합과 로라 겹쳐쓰기는 아주 유용하다기 보다는 이해를 위해 설명했습니다. 스테이블 디퓨전에 대한 변경된 이해를 기반으로, 뒤 파트를 익혀나가볼 수 있도록 하겠습니다. 우리는 이 덩어리를 Text2Image라고 이해했었지만, 이제는 텍스트 컨디셔닝이 들어가는 Basic Generation 입니다.