
학습목표
글을 다 읽으실 필요 없습니다! 차근차근 실습해보시거나 훑어보시면서 부담없이 따라오세요. :)
- Text 2 Image를 통해 어떻게 이미지를 만드는지 알아봅시다. 다시한번 고양이를 만듭니다.
- 좋은 계수값(파라미터) 조합을 찾기 위해 계수값테스트를 어떻게 하는지 알아봅시다. ← 중요!
Plain Text
복사
(우리는 1-3 그리고 4-1에서 스테이블디퓨전 모델에 대한 원리와 디테일을 조금 더 자세히 설명할 것입니다. 하지만, 이해하고 사용하면 응용력이 높아지는 것은 좋으나, 실무 상황에서 모든 요소를 이해하고 쓰는 것은 아닙니다. 즉, 평소에 이미지를 만들면서 하는 단순한 실무적 행위들을 중심으로 해당 챕터에서 요약해 알려드리는 것으로 합니다. 뭔가 이해가 가지 않거나 궁금해지시면 그때 1-1과 4-1을 참고하시면 됩니다. 단, 실력자가 되기 위해서는 원리 이해는 중요합니다. 그리고 해당 챕터에서는 KSampler와 Model을 중심으로한 Basic Generation을 설명하며, 다른 Core 요소와 함께 활용하는 건 5챕터에서 설명합니다. 다른 Core 노드들을 활용하는 것도 중요하지만, 일단 Text2Image가 어떤 상황에서도 강력한 중심이 되는 핵심 요소이기 때문에 Basic Generation 또는 Basic Pipe 또는 1st pass 라고도 부릅니다. 기본기를 잘 쌓아보도록 합시다.)
Text 2 Image로 이미지 생성하기
01. 목표설정 & 방법선택
일단 어떤 이미지를 만들지 충분히 상상해보고, 어떤 방법론으로 이미지를 구현할지 생각하는 시간을 잠깐 갖습니다. 우리는 텍스트로부터 이미지를 만들 것입니다. (만들고자 하는 이미지가 단순히 1장의 결과물이 아닌, 규모가 커지는 프로젝트일 경우에 중요한 내용이지만, 우선 한줄로만 적어둡니다.)
02. 프롬프트
일단 프롬프트를 작성합니다.
프롬프트 작성을 하는 방법은 다양합니다.
•
본인이 직접 영어로 작문하여 타이핑 할 수도 있고
•
그 과정에서 papago/google translater/deepl 과 같은 번역기를 사용할 수도 있고
•
챕터 3-3 chatgpt를 사용할 수도 있고 (ChatGPT를 PromptGenerator로 사용하는 방법은 사용하시는 분들이 있는 것으로는 알고 있지만, 팀 내부에서 자주 활용하는 방식은 아니라서, 다른 방식에 대해서 더 자세히 설명할 수 있도록 하겠습니다.
•
챕터 3-3 image를 text로 바꿔주는 clip interrogator/sLLM을 사용할 수도 있습니다. (sLLM과 관련해서는 향후 업데이트될 예정입니다.)
•
챕터 3-4 CivitAI, Openart, Midjourney, ImageTab과 같이 다른 사람들이 공개해둔 GenerationData를 참조하여, 본인이 필요한 형태로 변형해나가면서 활용할수도 있습니다.
사용할 수 있는 도구들에 대해 일단 여러가지 나열했습니다만, 원칙은 간단합니다.
긍정 프롬프트
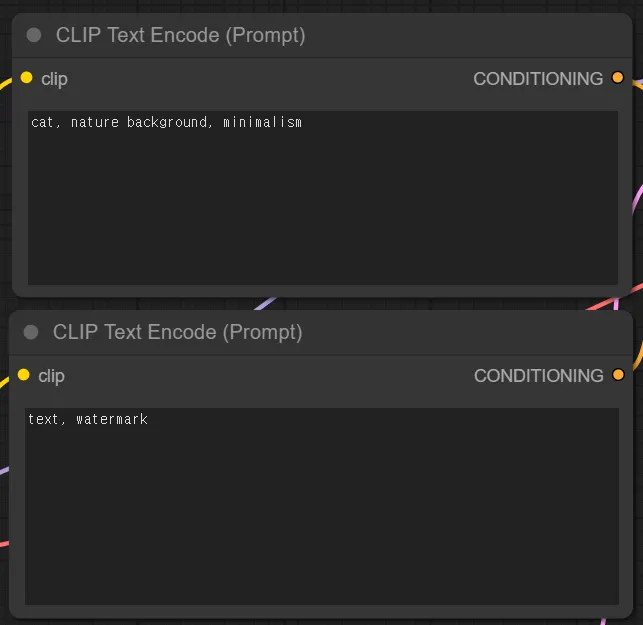
긍정 프롬프트에는 본인이 넣고 싶은 것을 넣고 (cat, nature background, minimalism, … )
부정 프롬프트
부정 프롬프트에는 본인이 빼고 싶은 것을 넣는 것입니다. (worst quality, nsfw, text, watermark, …)
(미드저니와 같은 대표적인 서비스와 비교하자면, 미드저니에는 부정 프롬프트를 입력할 필요가 없도록 해둔 것입니다.)
점진적 개선
처음부터 모든 프롬프트를 입력해두고 시작할 필요는 없습니다. 점진적으로 하나씩 추가해나가면서 개선하고 가다듬어나가면 됩니다. 기억하도록 합시다. 만들고 싶은 것을 긍정 프롬프트에, 빼고 싶은 것을 부정 프롬프트에 하나씩 추가해나간다.
03. 동작방식의 이해
스테이블디퓨전에서 흔히 ‘모델 즉 체크포인트가 이미지를 생성한다.’ 라고 생각하시는 경우가 많습니다. 물론 맞는 말이기는 하지만, 조금 더 정교하게는 KSampler가 체크포인트를 이용해 이미지를 생성한다고 이해하시는 것이 좋습니다.
Output = KSampler(Model, Prompt)
Plain Text
복사
이제 각각에 대해 설명할 수 있도록 하겠습니다.
04. 모델(=체크포인트)
아주 다양한 모델들이 존재합니다. 모델은 크게 체크포인트와 로라로 나뉩니다. 이 부분은 뒤에서 더 설명하겠습니다.
하지만 우선 처음에는 DreamShaperXL(dreamshaperXL_alpha2Xl10)을 사용해서 연습해보도록 합시다.
여기서 모델을 고정하고, 위에서 설명한 프롬프트, 아래 설명할 KSampler만 바꿔가면서 원하는 이미지들을 몇장 만들어보시길 추천드립니다.
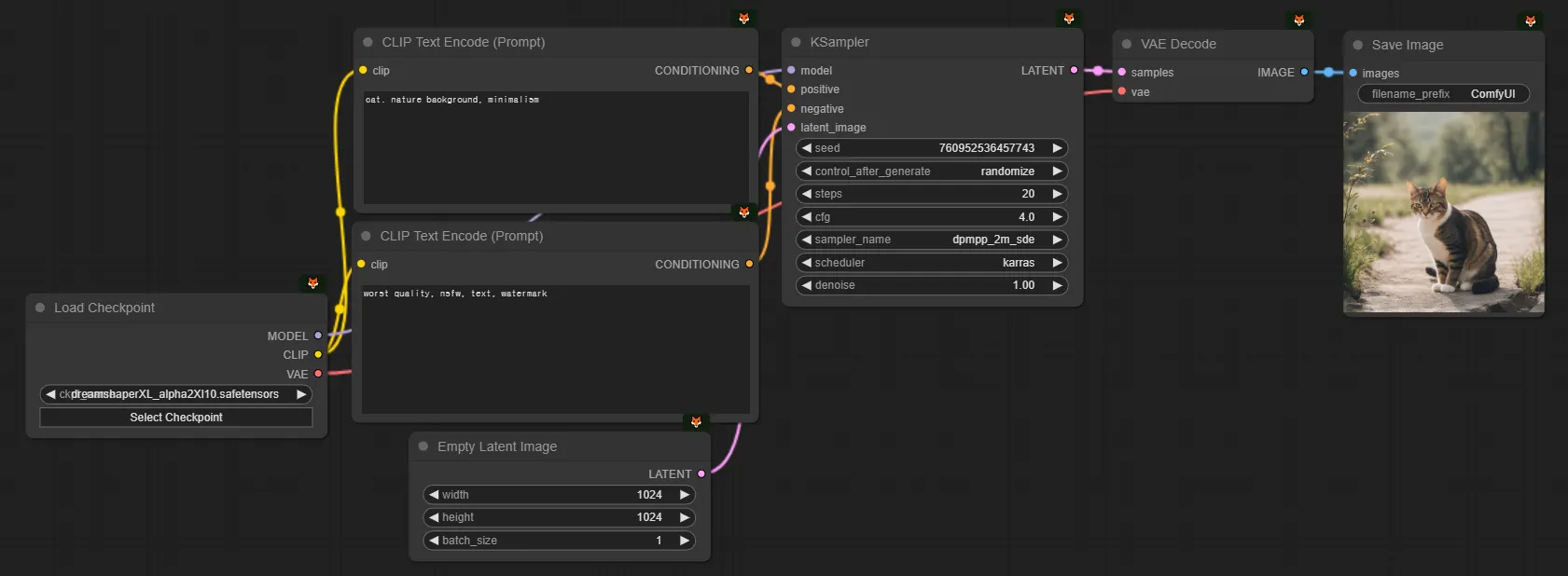
모델버전
스테이블 디퓨전에는 SD1.5, SD2.1, SDXL, SD3.0 같은 다양한 모델들이 존재합니다. (물론 Flux와 Pony같은 모델 계열도 존재합니다.)
저희는 그 중에 SD1.5, SDXL이 현재 주류(mainstream)이므로 이 두가지에 집중할 수 있도록 하겠습니다.
우선 딱 한 줄만 외우시길 바랍니다.
“SD1.5는 512로 학습되어 512이미지를 잘 뽑고, SDXL은 1024로 학습되어 1024이미지를 잘 뽑는다. SD1.5는 CFG 8이 무난하고, SDXL은 CFG 4가 무난하다.”
즉 제가 현재 위의 셋팅에서 SD1.5를 사용하기 위해 변화시키려면, [1] 모델 [2] 이미지사이즈 [3] CFG를 바꿔주시면 됩니다.
현재 저희가 XL모델을 쓰고 있는 것인지 1.5 모델을 쓰고 있는 것인지 정도는 쭉 인지하고 계시는 것이 좋습니다.
그래서 1.5 모델인 dreamshaper_8 모델로 바꿔주자면 이런 워크플로우가 됩니다.
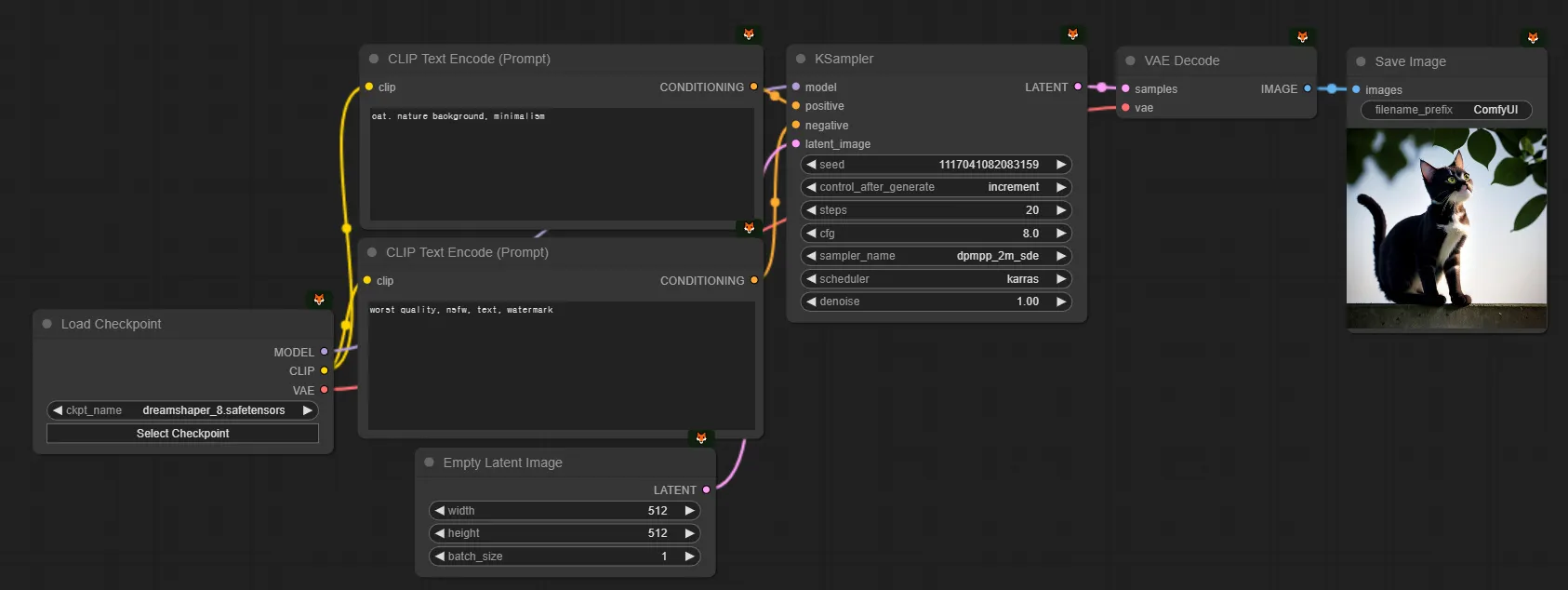
05. KSampler & SeedFix & 계수값테스트
(중요한 내용입니다! 시드픽스 후 계수값테스트 하는법은 꼭 알고가세요.)

앗 그런데, 위에서 뽑은 이미지가 뭔가 깨짐이 있고 마음에 들지 않습니다. 이 문제를 수정해보도록 하겠습니다.
우선 올바른 설정값으로 해주었는데 문제가 생기길래, 프롬프트에 오타가 있나 보았습니다. 오타가 있는 것 같진 않네요.
이럴때 일단 저희는 seed를 fix해줍니다. 랜덤하게 나오지 않고 현재 만들던 이미지에서 이어나가겠다는 뜻입니다.
KSampler에서 각 계수가 어떤 의미를 갖는지 조금 더 알아보고, 계수값 테스트를 배워가겠습니다. 다른 곳에서 잘 가르쳐주지 않는 내용이니, 이 튜토리얼 문서에서 계수값 테스트 하나만 건져가셔도 의미있을 정도로 중요한 내용이니 잘 따라와주세요.
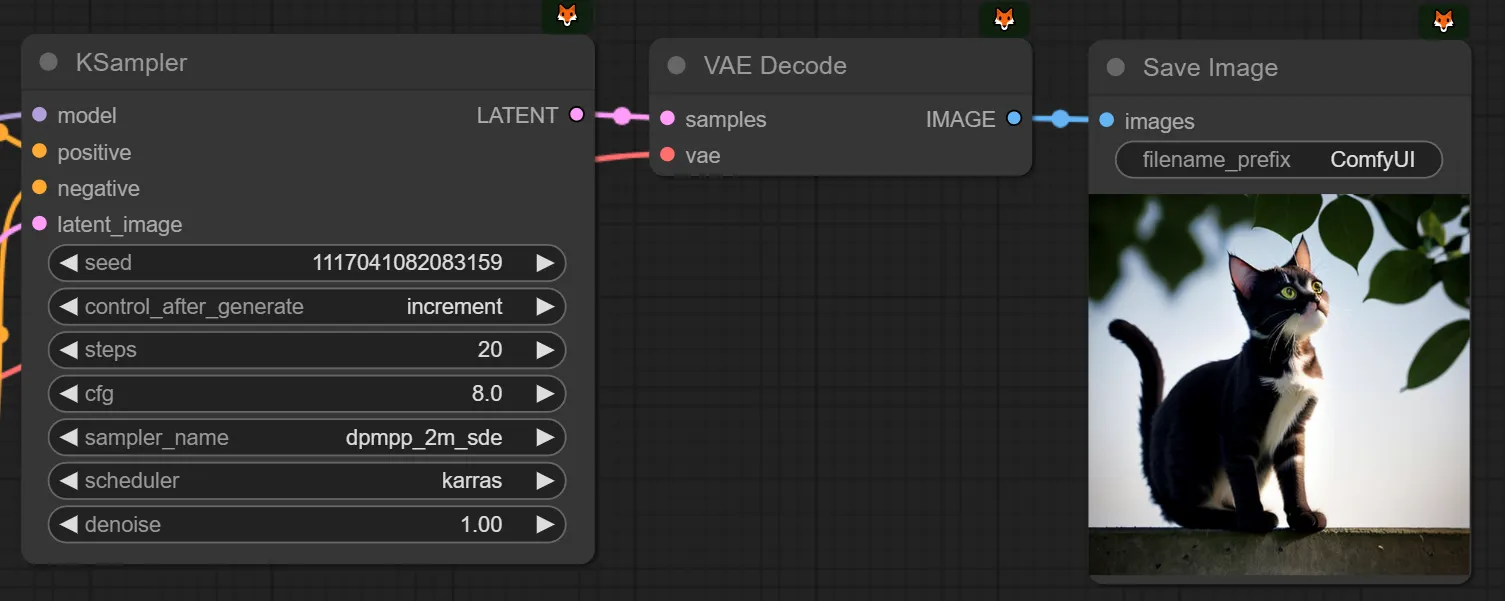
seed를 -1하고, control after generate를 increment에서 fix로 바꿔줍니다. ← 엄청 자주 하는 행위입니다! 익숙해지시길 바랍니다.
(seed를 increment/randomize로 설정해두면, 매번 생성할때마다 다르게 나오니, 이걸 고정해두면 같은 이미지가 나옵니다.)
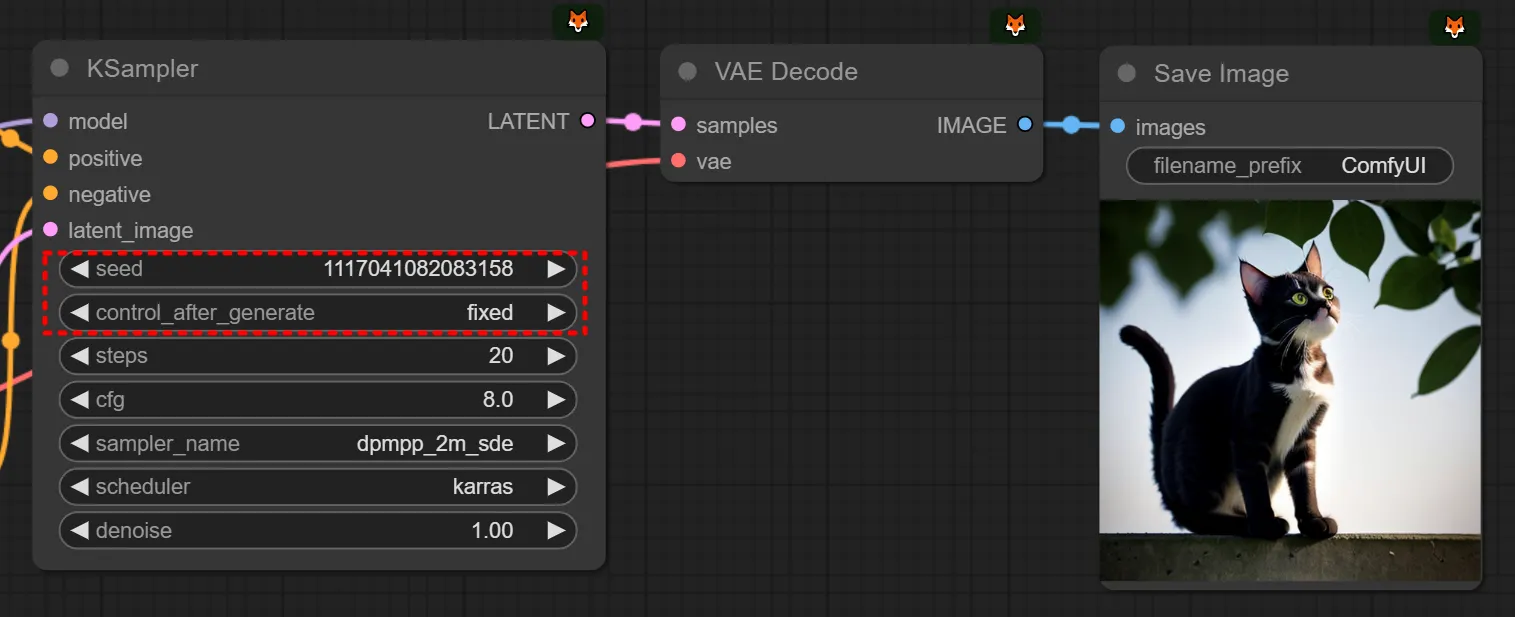
왜 시드를 -1했냐면, 이미지를 생성하면서 다음 이미지를 만들기 위해 seed가 올라갔기 때문입니다.
(저희가 방금 보던 아래 이 화면은 “방금 ‘seed=1117041082083158’로 이미지를 만들었고, 이제 너가 queue prompt를 누르면, 다음 이미지는 ‘seed=1117041082083159’로 만들 것임” 이라는 뜻이기 때문입니다. comfyui의 사용방법 자체가 아직 약간 복잡한 점에 대해서는 저희가 대신 양해를 구합니다. 그래서, 저희는 이러한 ‘계수값테스트’를 할 것을 염두에 두고 있기 때문에, randomize가 아닌 increment로 기본 설정해두는 것이 좋습니다. randomize로 설정해두면 테스트하기 조금 더 귀찮습니다.)
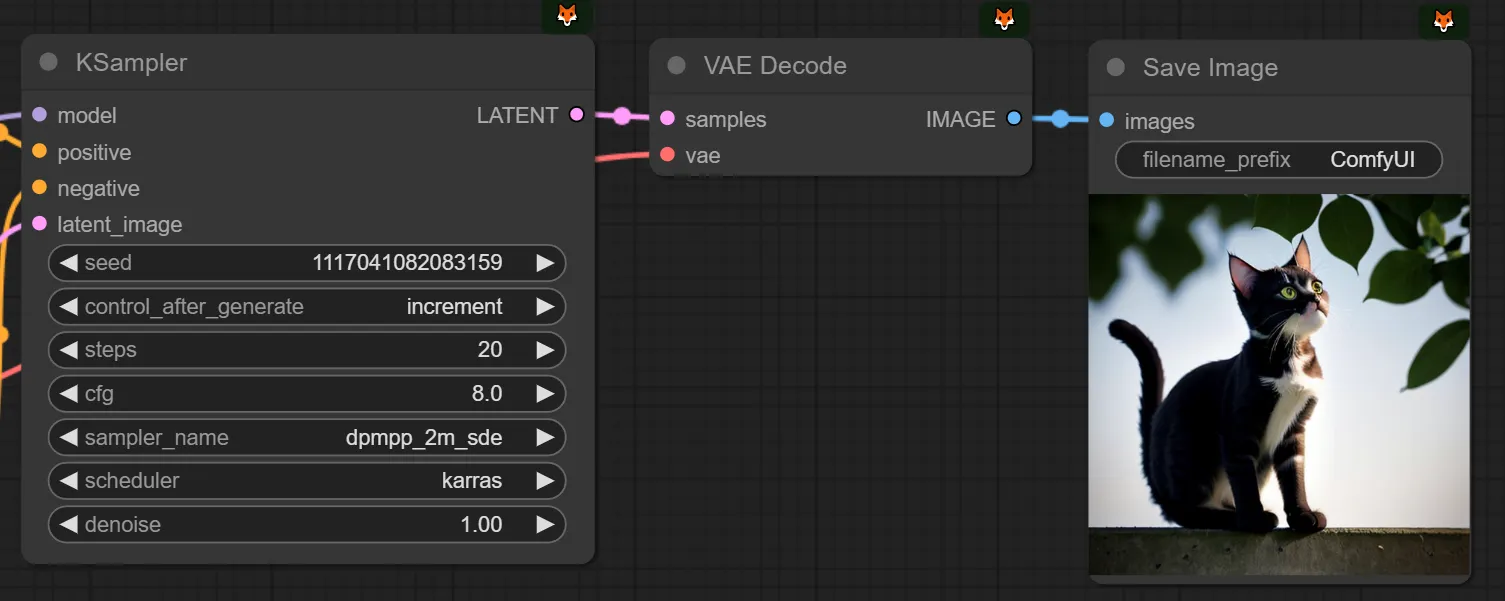
올바르게 시드픽스를 해두었다면, 동일한 이미지가 나오는 것을 확인하실 수 있습니다.
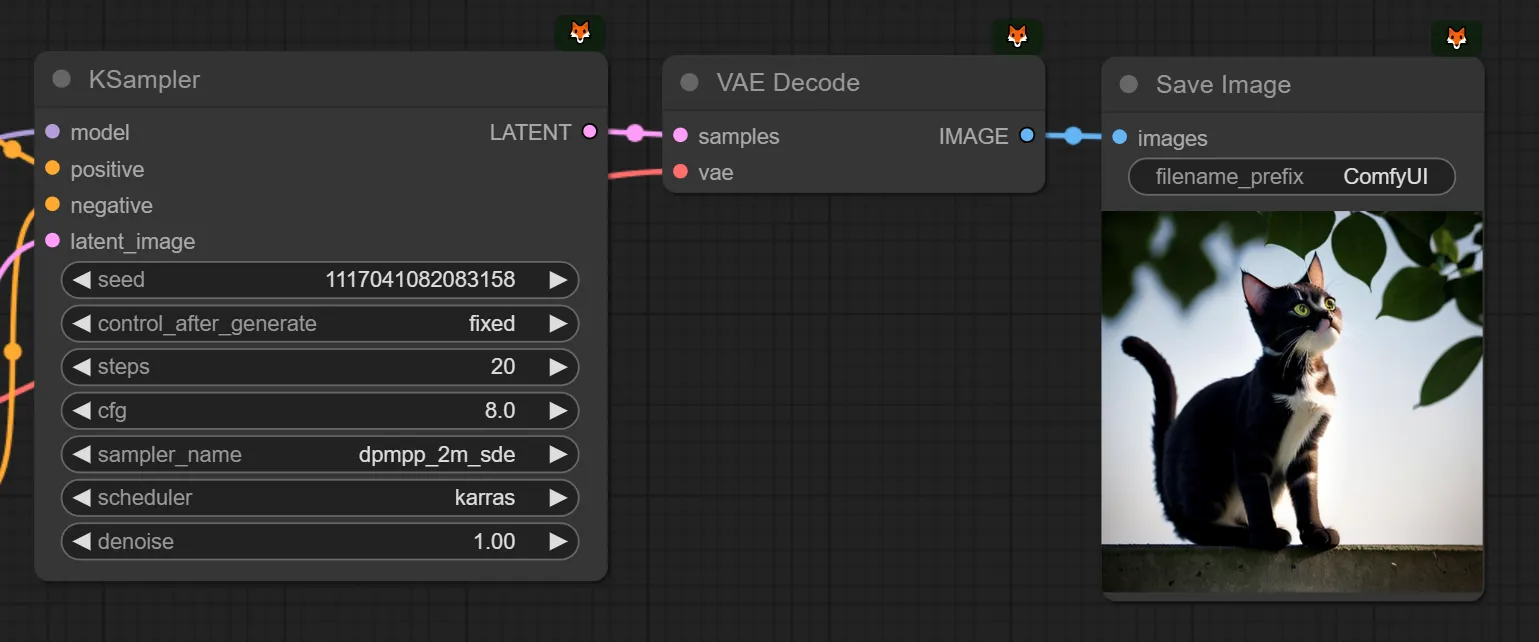
step을 20에서 30으로 변형해두어보았습니다.
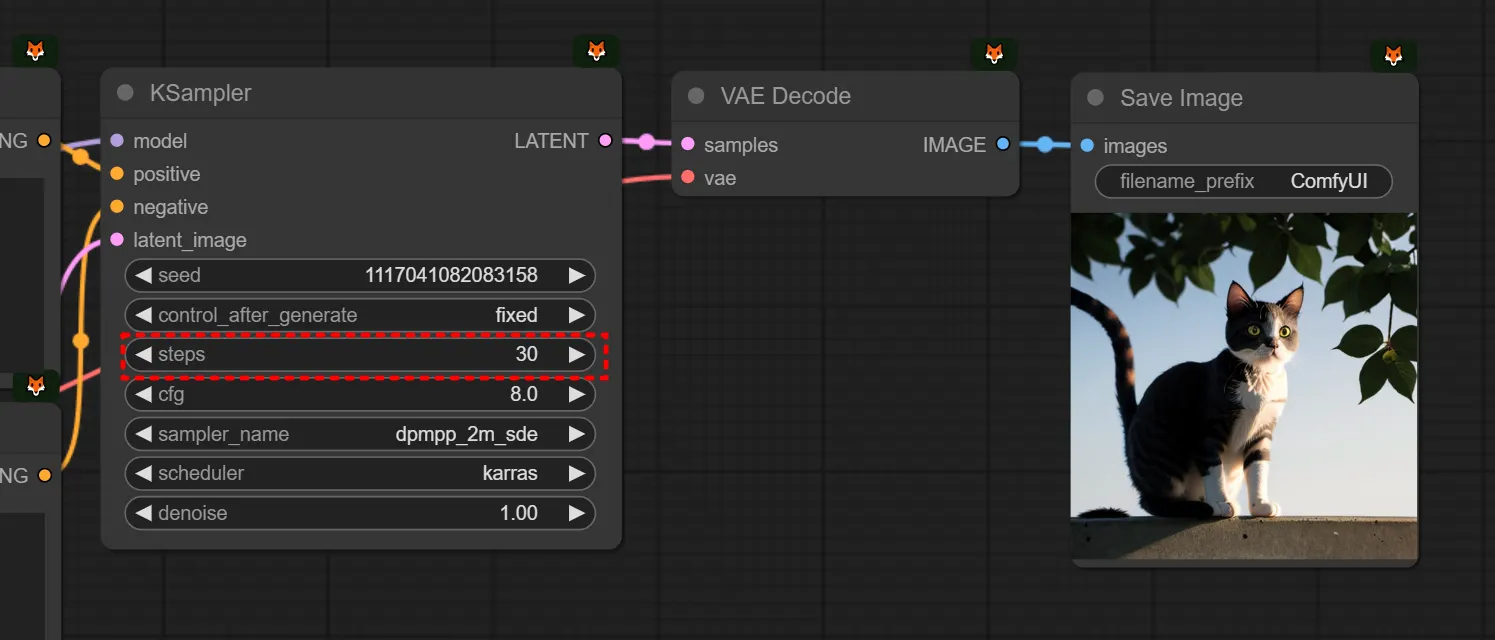
다시 step을 30에서 20으로 낮춰두고, cfg를 8에서 4로 낮춰보고, 이미지가 조금 더 개선되길래 다시 4에서 2로 낮춰보았습니다. 제 마음에는 조금 더 듭니다.
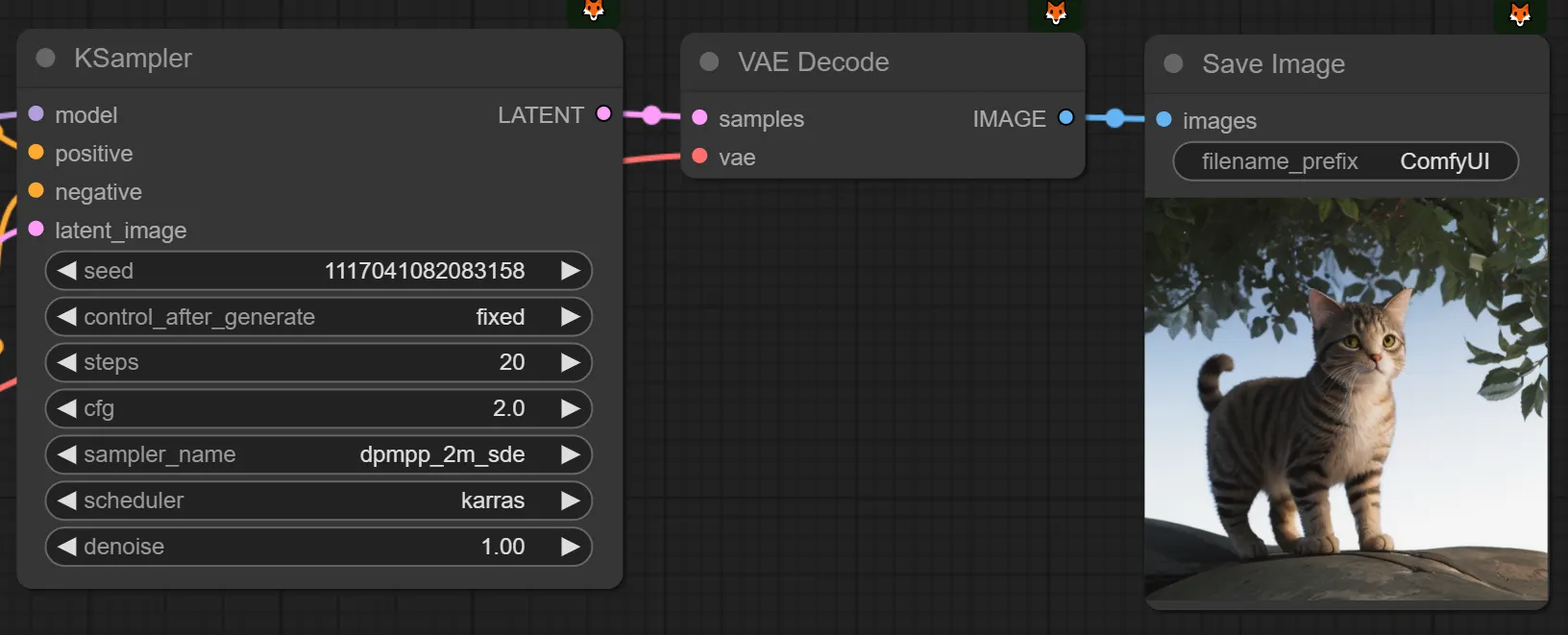
step을 30으로 두고 cfg를 2로 함께 설정했습니다.
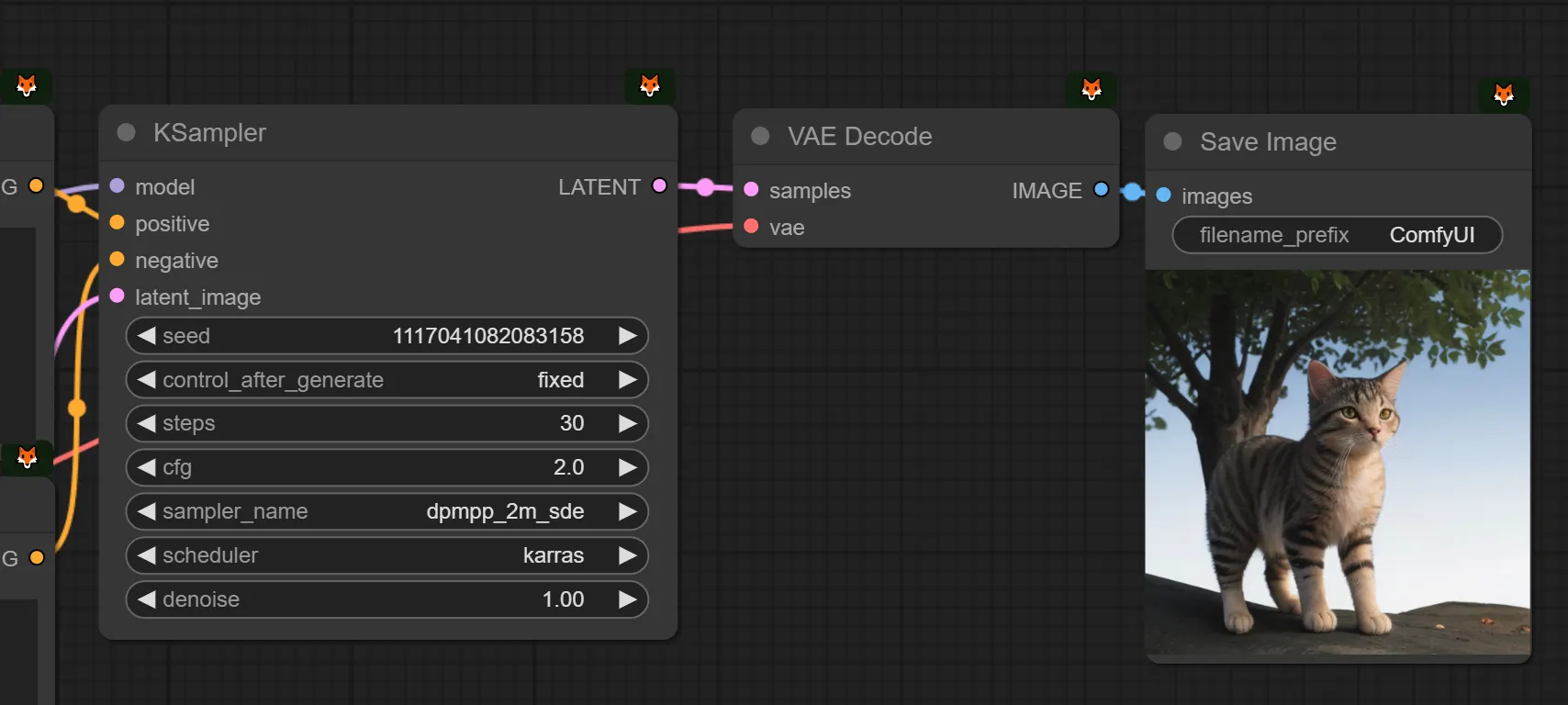
아까 SDXL로 만든게 더 마음에 들긴 했지만, 깨짐 현상은 개선이 되었습니다. 이 사진으로 셀렉하겠습니다.

다시 increment로 바꾸고 여러장 생성해보겠습니다. fix에서 increment로 바꿔준 직후에는 동일한 이미지가 다시한번 생성됩니다. 아까 seed를 -1했던 이유와 동일한 이유 때문이라고 생각하시면 됩니다. (이해 가시나요? 안가시면 위에서 -1 했던 지점을 다시한번 확인해주세요.)
이제는 나오는 이미지들이 조금 더 마음에 들어졌습니다. 하지만 타율이 100%로 좋지는 않습니다. 지금 한 작업이 간단한 수준의 계수값 테스트라고 생각하시면 됩니다. 이 모델로, 이 프롬프트를 쓸때, 이 값이 나에게는 마음에 든다. 를 정해나가는 과정이라고 보시면 되겠습니다.
모든 것을 동일하게 통일시켜두고, 각 요소들이 어떤 변화를 주는지 관찰하고 조정하는 것입니다. 계수들을 하나만 변경했던 이유는, 실험을 할때 두세가지를 한번에 바꾸고 결과를 관찰하면 그 두세가지 요인중에 무엇이 영향을 준 것인지를 측정하기 어렵기 때문입니다.
물론, 이 값은 절대적인 것이 아니며, 더 나은 레시피가 있었을수도 있고, 이 값이 항상 잘 먹는 것은 아닙니다. 하지만 절대적인 ‘이런 계수가 항상 좋아요’는 없고, 매번 어느정도 실험해가며 맞는 값을 찾아가는 과정이라고 보시면 됩니다.

위에서 seed, control_after_generate에 대해서는 설명했고, 나머지 요소들에 대해 설명하겠습니다.
steps | KSampler가 seed로 부터 이미지를 만드는데, steps이 20이면 20번에 걸쳐 이미지를 만들고, 30이면 30번에 걸쳐 이미지를 만든다고 생각하시면 됩니다. 단, step이 30이면 생성시간도 20일때에 비해 3/2배 더 걸립니다. steps를 제외한 나머지 요인은 시간에 영향을 주지 않습니다. |
cfg | 프롬프트의 영향을 더 많이 받게 하는 것입니다. cfg를 높이면 프롬프트의 영향력이 강해집니다. 낮추면 프롬프트의 영향력이 약해지고, 모델이 프롬프트를 덜 신경쓰고 자유롭게 이미지를 만듭니다. cfg가 클수록 이미지의 시각적 대비(contrast)가 강해지는 경향이 있습니다. |
sampler_name | 어렵게 말하자면 KSampler가 step이 20일때 디노이징과 샘플링을 20번 한다고 생각하시면 되는데, 그때 샘플링을 어떻게 할 것인지를 결정하는 함수의 종류라고 생각하시면 됩니다. 함수가 뭔지 현재 시점에는 이해할 필요가 없으나 향후에 원리를 이해하시면 좋습니다. |
scheduler | 쉽게 말하자면 sampler와 scheduler는 궁합이 있다 정도로 기억하시면 됩니다. |
denoise | text2image를 할때는 이 값을 조정할 필요는 없습니다. 1로 고정하면 됩니다. 물론 낮추면 이미지가 덜 완성되는 방향으로 변합니다. |
그럼 위의 설명에 따르면, steps, cfg, denoise는 수치를 증가 또는 감소 시켜나가면서 변화시켜보면 됩니다. 하지만, sampler와 scheduler는 어떻게 결정하면 좋을까요? 일단 아래 3가지를 추천드립니다. 아래 3가지를 바꿔 사용해보시면서, 그 차이를 느끼셔보면 좋을 것 같습니다. (그리고 실력자가 되어가시는 과정에서 추가적으로 본인에게 잘 맞는 값들을 알아나가보세요.)
sampler | scheduler |
euler | normal |
dpmpp_2m_sde | karras |
dpmpp_3m_sde | exponential |
우선 실험해보기 귀찮다면 우선 dpmpp_2m_sde, karras 조합으로 사용하시다가, 나중에 이미지 개선이 필요한 시점에 바꿔보시는 것을 추천드립니다. 더 일목요연하게 케이스를 정리해드리고 싶은데, 경우의 수가 너무 많아, 일단 저희는 이 조합으로 90% 이상의 작업을 처리하곤 합니다.
그리고 참고적으로, 샘플러에서는 이름이 비슷한 친구(시리즈)들이 있는데, 그 사이에서는 모델마다 조금 다른 경우가 있어 퀄리티 업을 위해 실험해볼 여지가 있습니다. 예를들어 언제는 권장드린 dpmpp_2m_sde이라고 하더라도, 언제는 dpmpp_sde를 할때 잘 나오고, 언제는 dpmpp_2m_sde_gpu를 쓸때 잘 나오고 하는 패턴이 존재합니다.
07. Latent
이미지 사이즈를 지금까지는 정방향 (1:1 비율) 이미지만 만들었지만, 실무 상황에서는 3:4, 4:3, 9:16, 16:9 등 다양한 이미지를 만들게 됩니다. 이때 Latent Size를 가볍게 변경해주면 끝입니다. (이때 이미지 사이즈를 어떻게 결정하는지에 대해서는 3-4 ImageSIze에서 설명되어있습니다.)
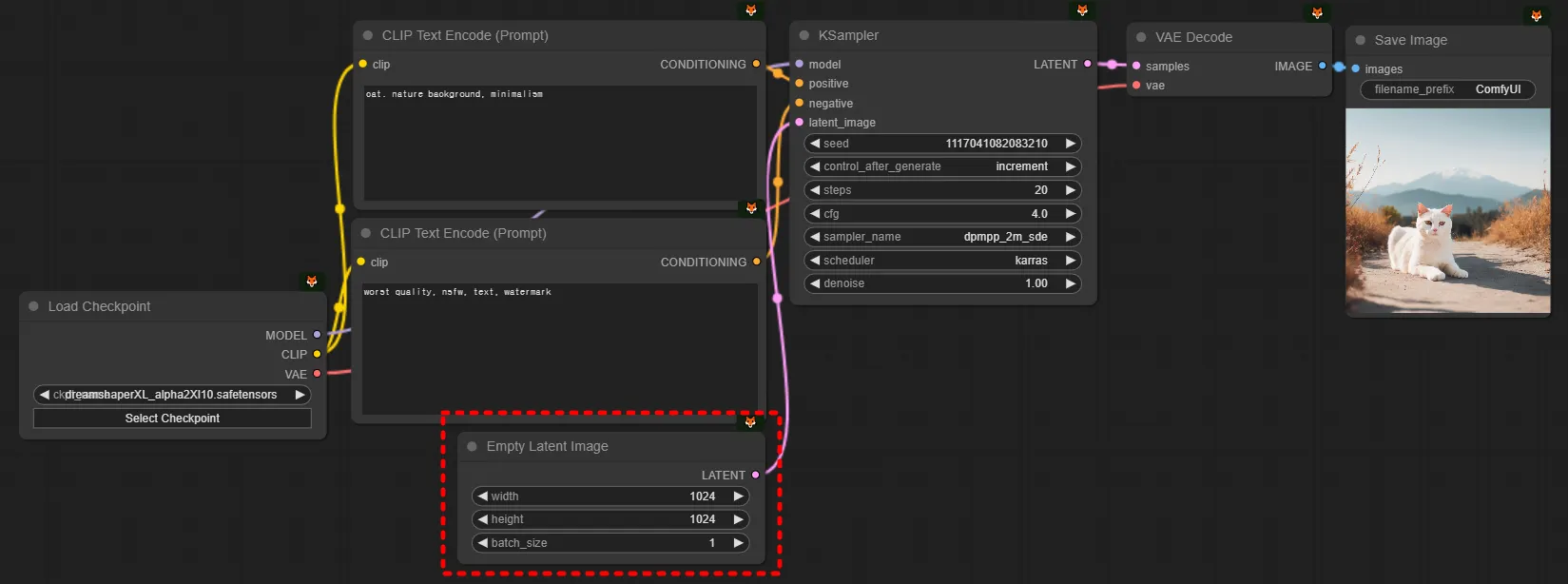
추가적으로 한가지 설명만 드리자면 Latent에 대한 개념 정도에 대해서는 아주 간단한 수준으로 이해해두시는 것이 반드시 좋습니다. Latent와 관련된 설명을 추가해보겠습니다. ‘03.동작방식의 이해’에서 설명했던 것을 조금 이어나가보겠습니다. 위에서는 이렇게 설명했었지만, 이건 사실 틀린 설명입니다.
Output = KSampler(Model, Prompt)
Plain Text
복사
한번 더 올바르게 해당 함수 관계를 발전시켜보면 다음과 같습니다.
OutputLatent = KSampler(Model, Prompt, Latent)
OutputImage = VAE_Decode(OutputLatent)
Plain Text
복사
(잠시 딱 1분만 어려운 용어들이 나옵니다. 쫄지 맙시다. 쉽습니다. 아래 설명을 읽으시면 이 그림 3장을 독해하실 수 있게 됩니다. 아직 text2image 이야기만 하고 image2image에 대한 이야기는 하지 않았지만, 대충 image2image를 예측할 수 있게 됩니다.)
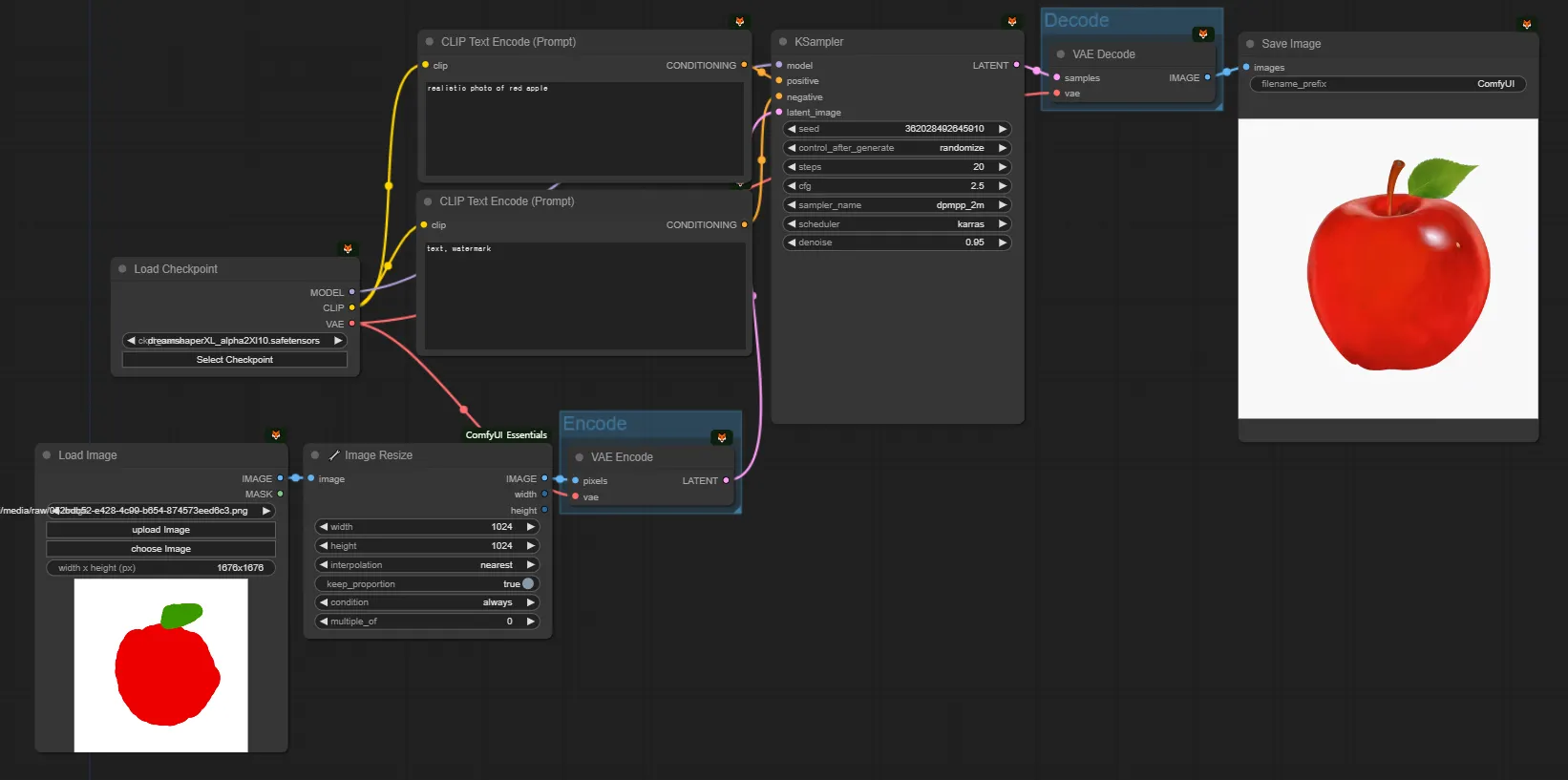
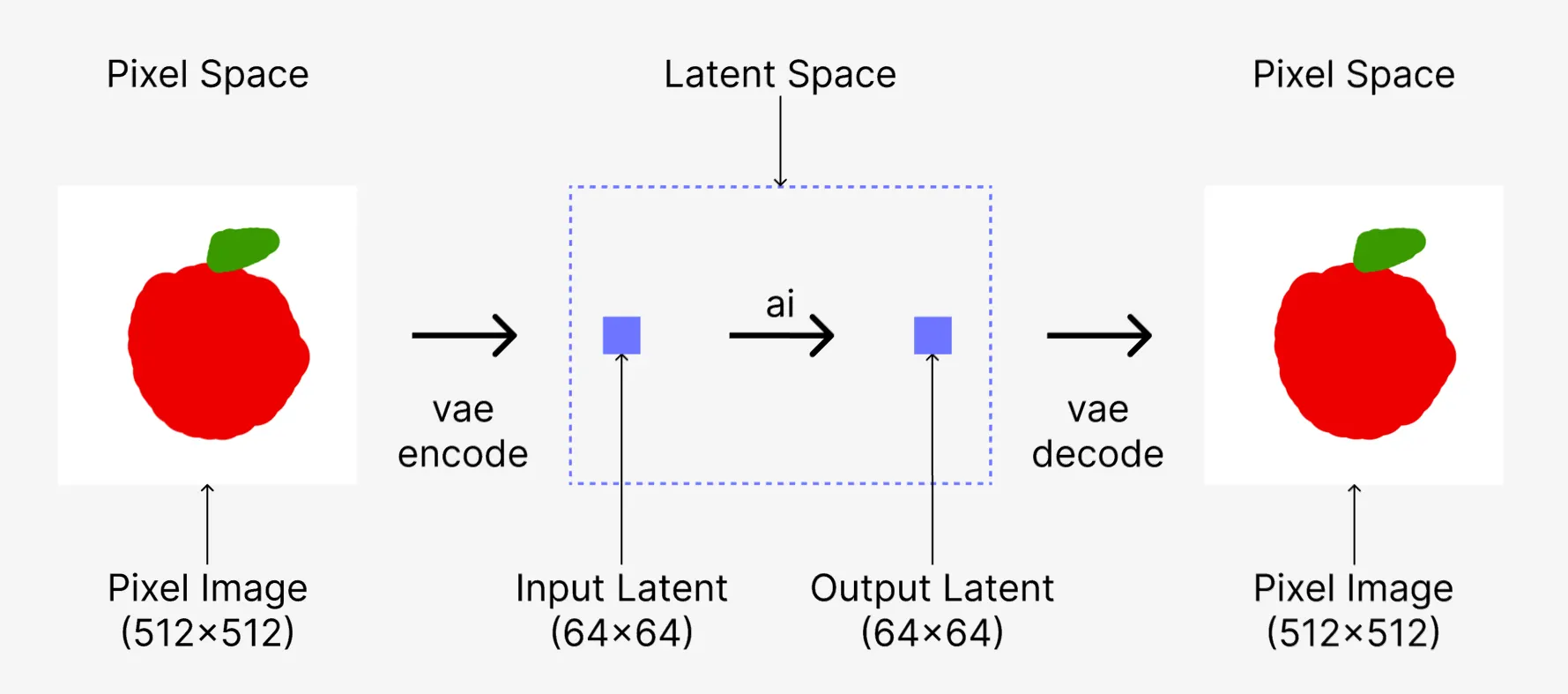
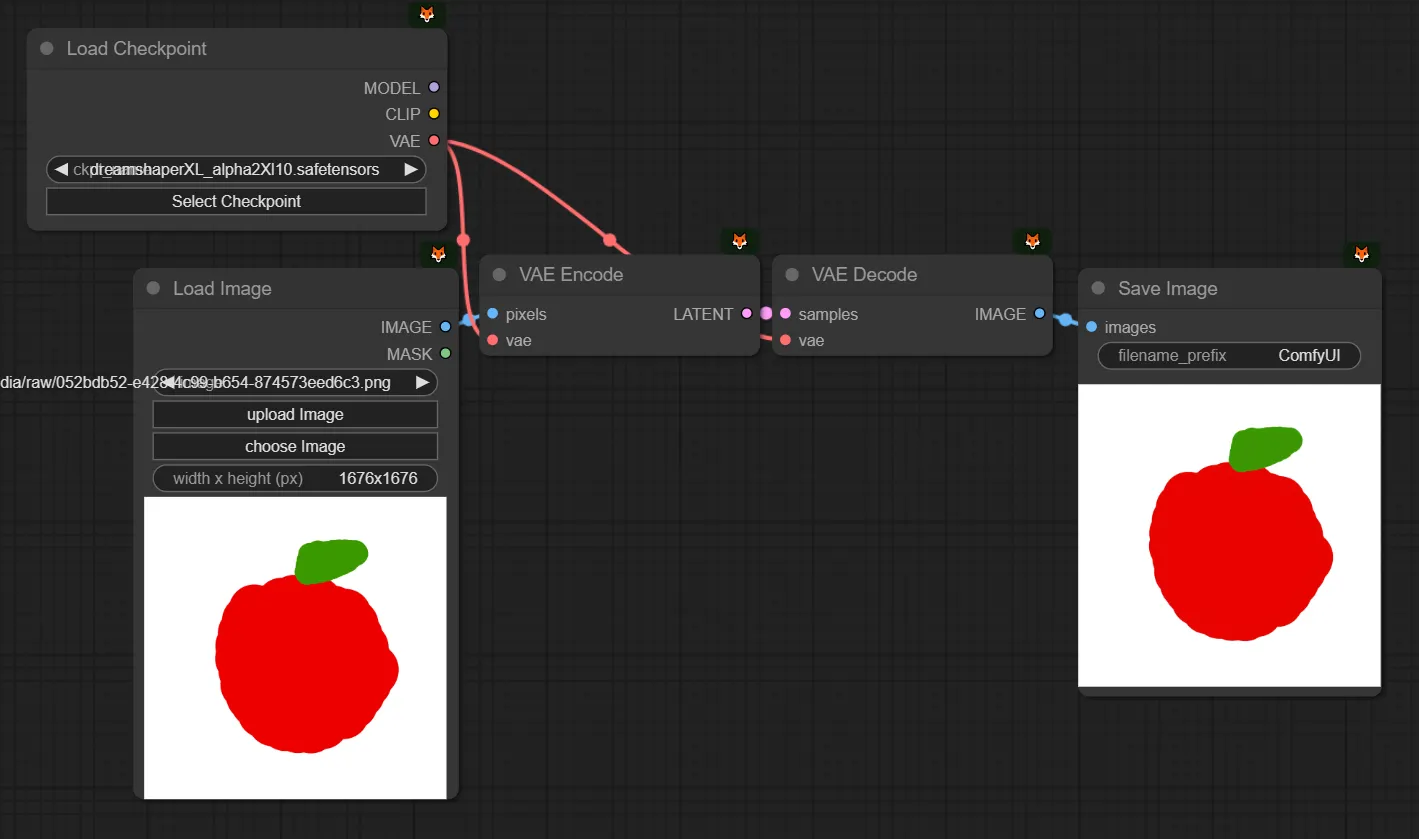
“우리가 보는 Image는 Pixel이고, Pixel과 Latent는 다른 거다. 사람은 이미지를 보기 위해서 Pixel을 통해 보지만, ai가 보기 위해서는 Latent로 바꿔줘야 한다. KSampler는 Latent를 처리한다.” 외웁시다!
그래서, 비어있는 1024x1024 사이즈의 이미지를 만들어서, KSampler에게 VAE를 통해 Pixel로 된 Image를 Encode해서 Latent 형태로 만든 이후에 전달해주고, KSampler가 만든 Latent를 다시 VAE를 통해 Decode해서 latent에서 pixel로 변환해준 다음에 보는 것입니다.
여기서 vae 라는 얘가 하는 역할은, latent와 pixel간의 변환을 해주는 역할을 하는 것으로만 이해하셔도 괜찮습니다. 이 문서가 끝나기 전까지 vae를 이 목적 말고 다른 목적으로 쓰는 경우는 등장하지 않으므로(1-3 제외), vae는 그냥 체크포인트에 있는 것을 연결해주기만 하는 것으로 합니다.
(Encode한다. Decode한다. 이 또한 컴퓨터공학의 책에서 나올것만 같은 어려운 표현입니다…! 쉽게, 일종의 압축/압축해제의 관계로 이해하셔도 좋습니다. latent로 압축했다가 image로 압축해제. 또는 변환이라고 이해하셔도 됩니다. 저희는 변환이라는 표현을 쓸 수 있도록 하겠습니다.)
ksampler에게 이미지를 직접 넣어주면 안되고 vae를 통해 latent로 변환해주고 넣어줘야 하고, ksampler가 만든 latent output은 vae를 통해 pixel 형태의 이미지로 바꿔야 한다는 사실 정도의 관계만 익혀두시면 되겠습니다.
모델(again)
어려운 개념 익히느라 고생 많으셨습니다. 이제 2-2에서 어떻게 Text를 이용해 이미지를 만드는지 방법을 이해했다면, 챕터4로 넘어가서 Core 노드들을 어떻게 이용하는지 공부해보면 좋을 것 같습니다. 단 바로 챕터4로 넘어가기 전에, 챕터3는 필요하실때 활용하실 수 있도록 가볍게 훑어보고 넘어가시면 좋을 것 같습니다.
(그 전에, text2image로 연습을 조금 해보고 넘어가시는 것을 추천합니다. 아래 이미지들을 통해 다양한 모델 및 로라가 어떻게 이용되었는지 응용해보시고 연습하면 좋을 것 같습니다. 3-4에서 외부 플랫폼을 잘 활용하는 법에도 써두었긴 하지만 중요한 대목을 하나 말씀드리면, ‘문서’를 잘 읽으시면 좋습니다. 커스텀노드가 아니라 체크포인트일지라도, 그 체크포인트를 만든 사람이 이 체크포인트는 어떻게 만들었고, 어떻게 사용하는 것이 좋고, 이 모델을 쓰는 사람들은 어떤 작업물들을 만들었고, 그때 어떤 설정값 또는 프롬프트들을 썼었는지 등 많은 정보들이 있어, 그런 정보를 가볍게 탐색하신 뒤에 모델을 쓰시는 것이 좋습니다. 늘 그런 절차를 밟을 필요는 없지만, 뭔가 잘 안된다 또는 더 잘 되게 만들고 싶다라는 생각이 들때는, 일단 문서를 가볍게 한번 참고하시는 것은 언제나 좋습니다.)
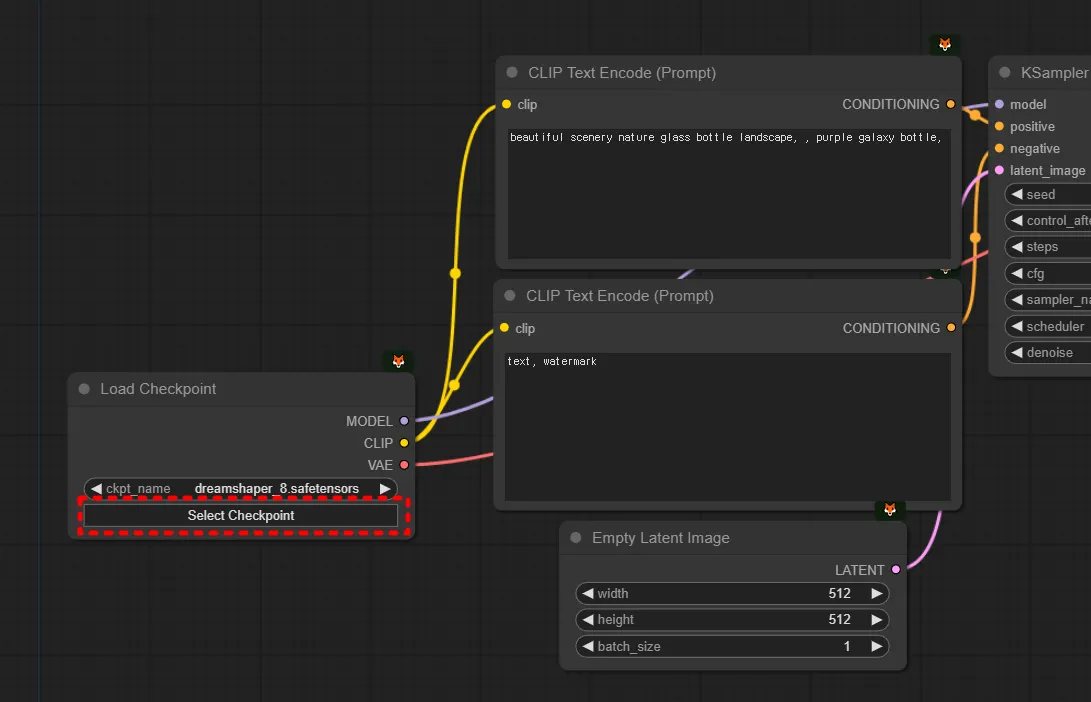
체크포인트 사용법
위에서 설명드렸습니다. Select Checkpoint를 눌러 다른 체크포인트로 변경해서 사용하시면 됩니다.
(현재 본인이 SD1.5를 쓰는지, SDXL을 쓰는지에 따라, 설정이 달라집니다. 우선 SDXL을 추천드립니다.)
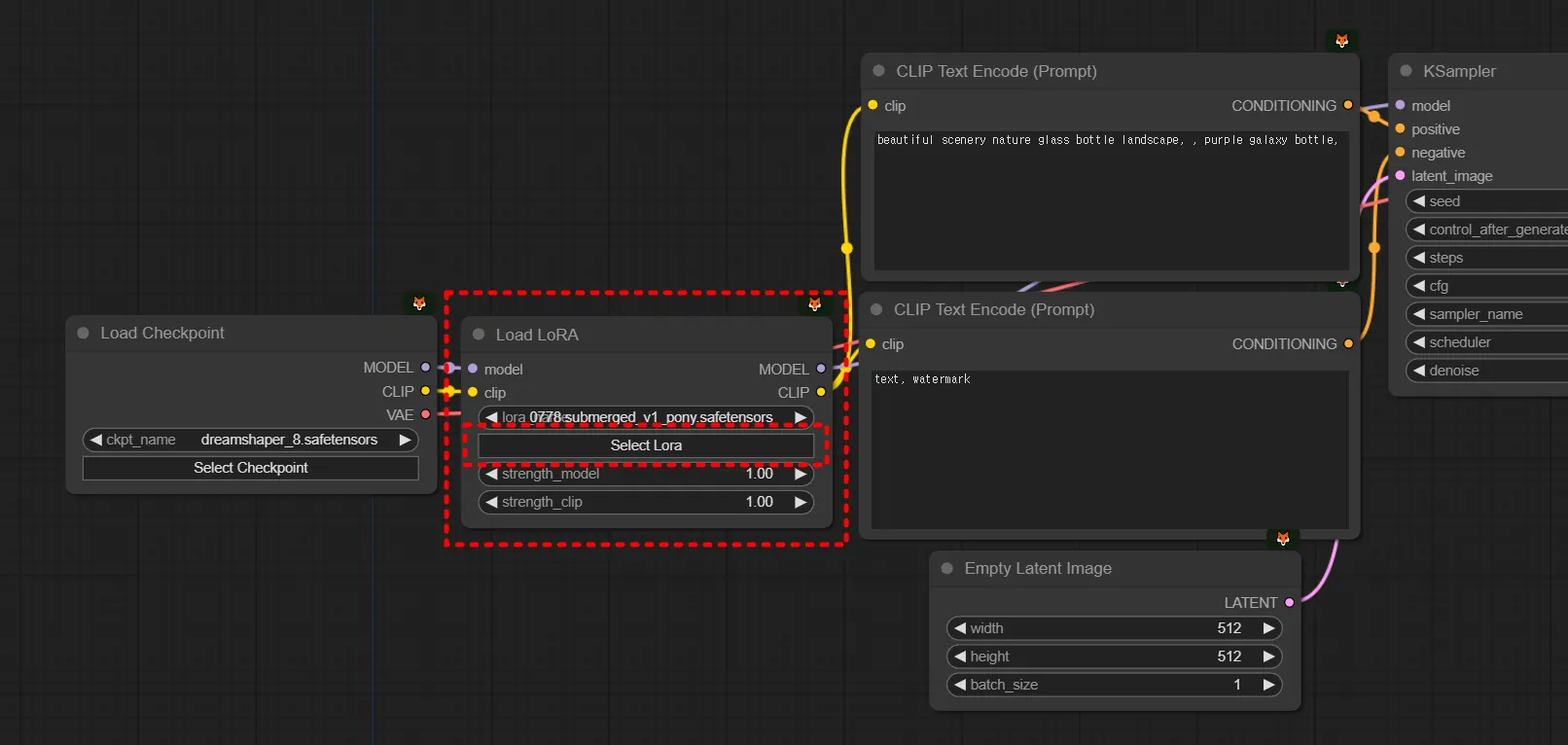
로라 사용법
Load LoRA 노드를 불러옵니다. 모델과 샘플러 사이에 아래 연결관계로 끼워줍니다.
1.
comfyui 빈 화면을 더블클릭해서 load lora 검색해서 불러오기
2.
checkpoint, prompt, ksampler 사이에 연결해주고, model과 clip 연결하기
(단, SD1.5 체크포인트를 쓰면 SD1.5 로라를 써줘야하고, SDXL 체크포인트를 쓰면 SDXL 로라를 써줘야 합니다.)
체크포인트/로라 몇가지 추천
(2024년 7월 31일 작성)
한번 가볍게 둘러보시고, 프롬프트와 계수값을 변경해가며 응용해보세요! 이 추천은 항상 언제나 좋다거나 하는 절대적인 것은 아니며, 작성시점에 civitai에 보이는 또는 평소에 이용하던 모델들을 갖고 가볍게 몇가지 작업을 해본 것입니다. 계수값도 이 모델은 항상 이 값이 좋다거나 하는 것은 아니며 늘 계수값 테스트는 필요합니다. 공부의 첫 걸음에 도움이 되기를 바랍니다.
다시한번, 내가 XL모델을 쓰는지 1.5모델을 쓰는지는 늘 염두에 두어야 합니다. 두가지를 섞어쓸 수는 없습니다.
.png&blockId=4b590096-3158-4bc7-9401-584ec85ede9f)
SD Version | Ckpt/LoRA | Style | Name | Nordy URL | CivitAI URL |
SDXL | Checkpoint | photorealistic | epiCRealism XL | ||
Juggernaut XL | |||||
anime | 万象熔炉 | Anything XL | ||||
Animagine XL V3.1 | |||||
3D | DynaVision XL | ||||
LoRA | photorealistic | SDXL Film Photography Style | |||
Perfect Eyes XL | |||||
anime | LineAniRedmond- Linear Manga Style for SD XL | ||||
Aesthetic Anime LoRA | |||||
3D | Samaritan 3d Cartoon SDXL | ||||
Vector | Vector Cartoon Illustration | ||||
SD 1.5 | Checkpoint | photorealistic | Realistic Vision V6.0 B1 | ||
epiCRealism | |||||
anime | ReV Animated | ||||
MeinaMix | |||||
3D | NeverEnding Dream (NED) | ||||
Disney Pixar Cartoon Type A | |||||
LoRA | anime | Anime Lineart / Manga-like (线稿/線画/マンガ風/漫画风) Style | |||
Studio Ghibli Style LoRA | |||||
3D | blindbox/大概是盲盒 | ||||
3D rendering style |