
Chapter 3 doesn't need to be read in sequence!
Think of it as a reference document that you can consult as needed.
Learning Goals
"Exploring Text2Image, a valuable tool for Image2Text."
Plain Text
복사
Why it's needed
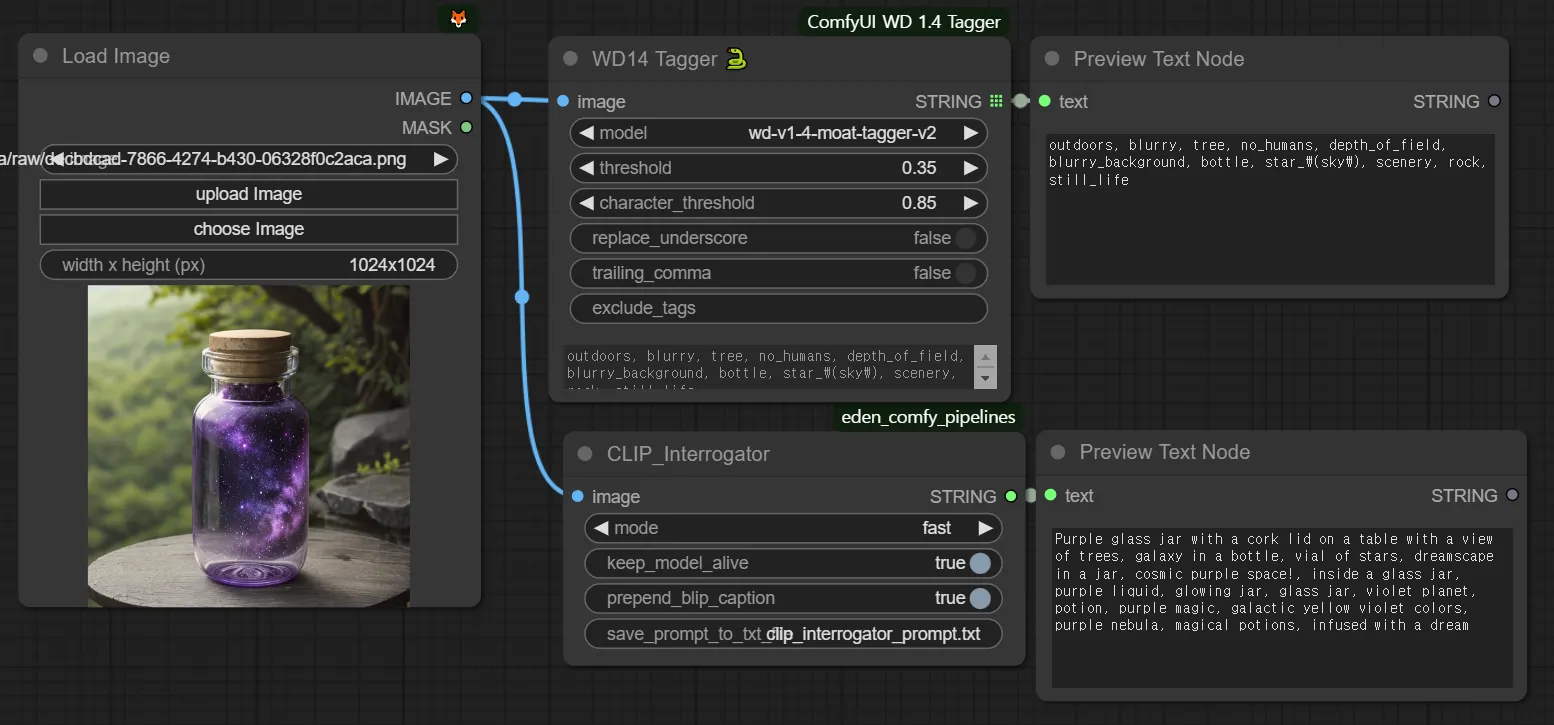
There are nodes that convert images to text.
These are very useful, so it's important to understand and use them when needed.
Why is it necessary? Humans are not very good at converting images into text.
Look at this photo and try to describe it in words. You can use either Korean or English. What words come to mind?

WD Tagger
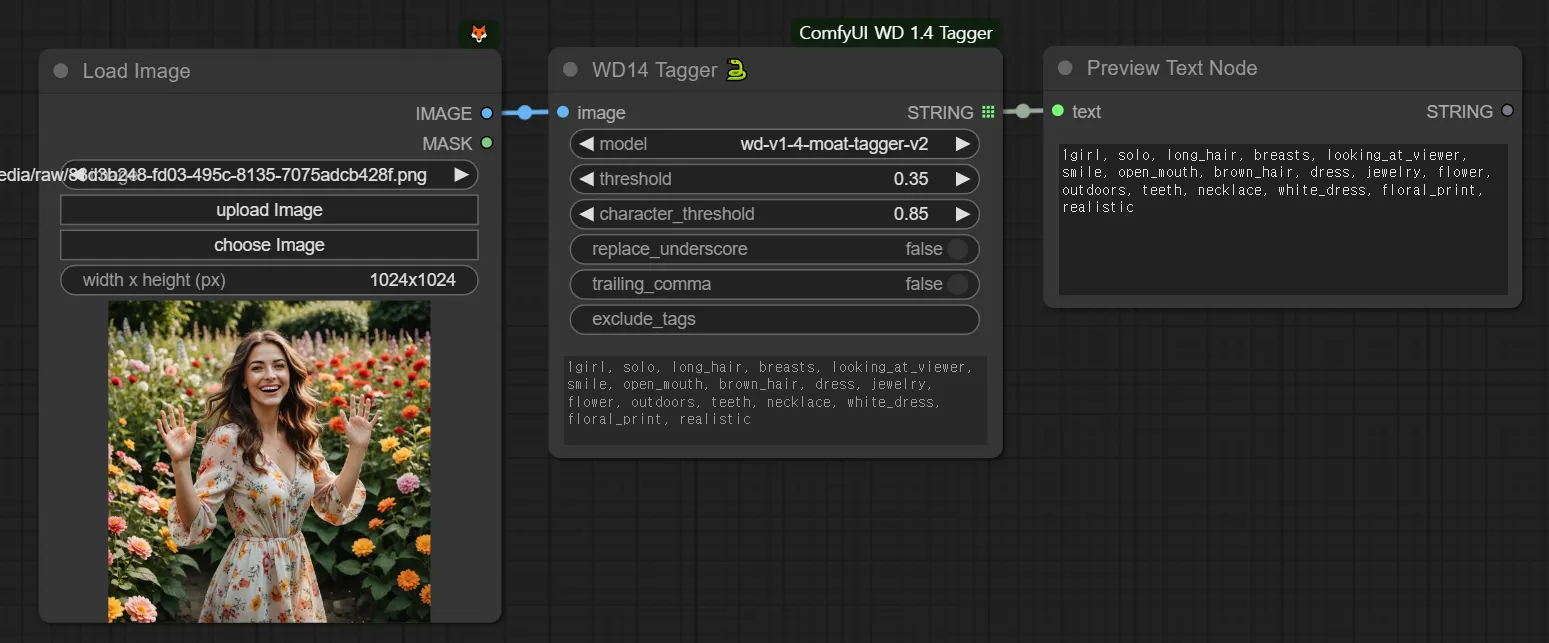
1girl, solo, long_hair, breasts, looking_at_viewer, smile, open_mouth, brown_hair, dress, jewelry, flower, outdoors, teeth, necklace, white_dress, floral_print, realistic
However, using a Tagger can provide you with words like these. They are fairly decent.
The situation isn't described very well. Actions like standing with outstretched arms aren't captured.
Nevertheless, words like "1girl," "solo," and "long_hair" appear, which are common in prompts used by people.
This is because Tagger is used in the process of creating Checkpoints/LoRA (i.e., training, fine-tuning, Kohya).
So, you can understand that such terms will be used for learning if this data is automatically trained.
Clip Interrogator
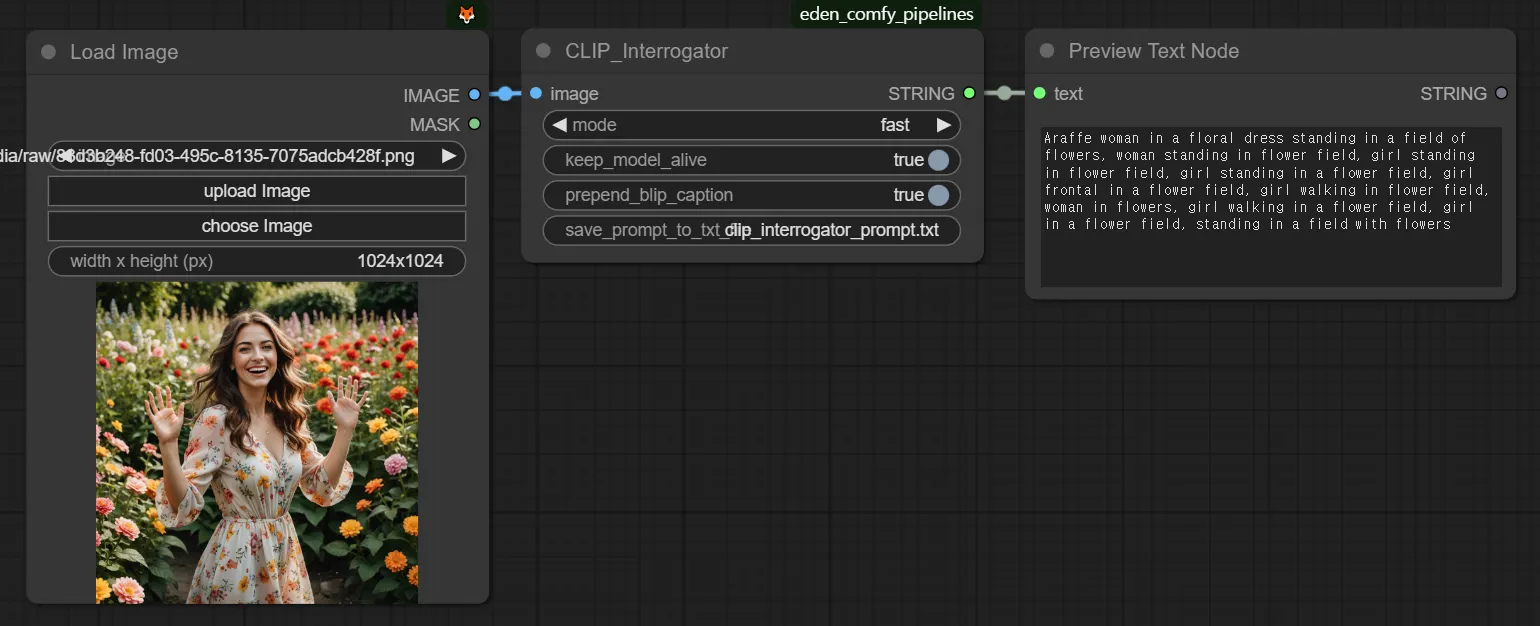
Araffe woman in a floral dress standing in a field of flowers, woman standing in flower field, girl standing in flower field, girl standing in a flower field, girl frontal in a flower field, girl walking in flower field, woman in flowers, girl walking in a flower field, girl in a flower field, standing in a field with flowers
Using Clip provides a more detailed description. It seems closer to what we were expecting.
You can use this as a reference to see how such photos can be described and use it to write better prompts.
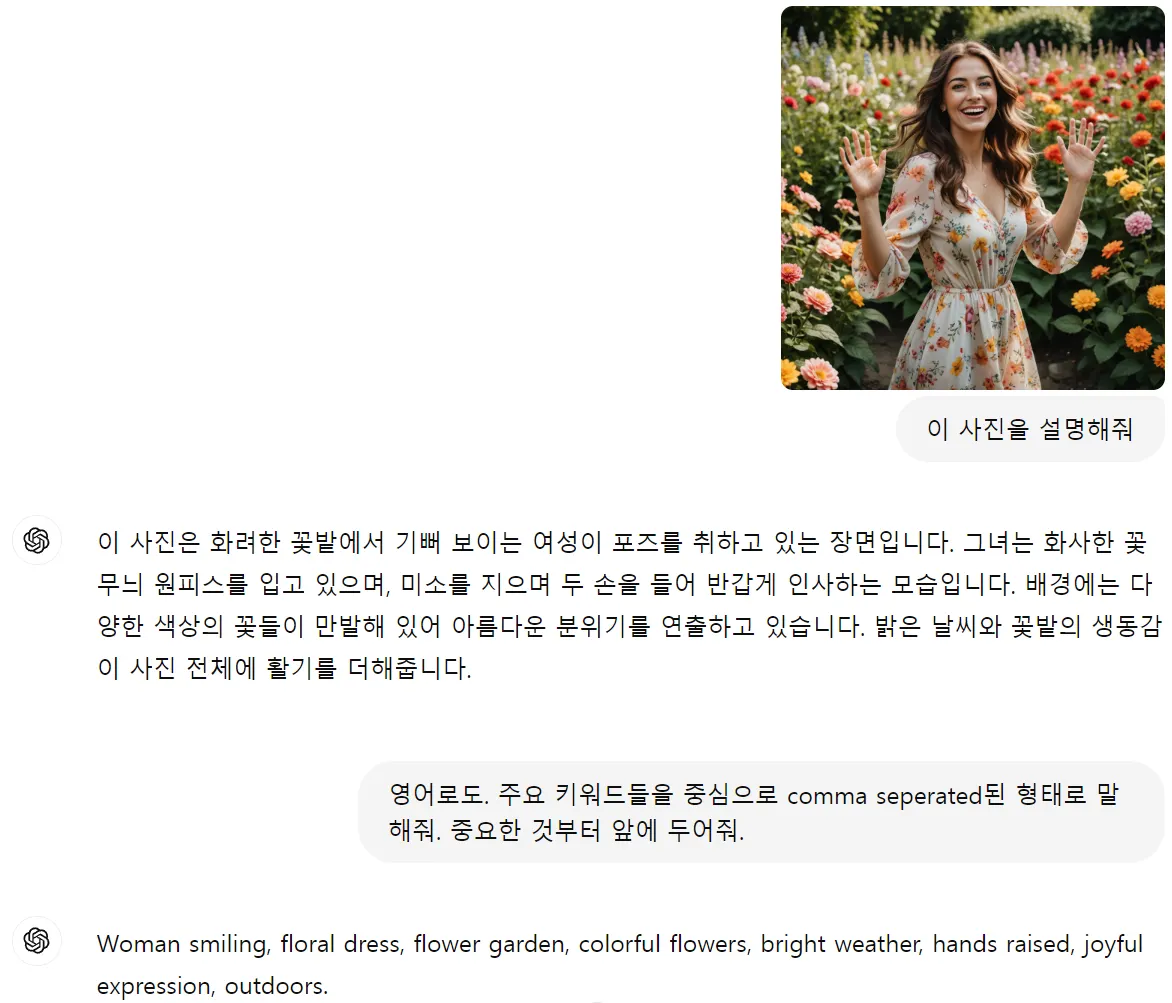
ChatGPT
Many attempts are being made to use ChatGPT as a prompt generator for StableDiffusion, but such ChatGPT prompts are not commonly used. Since GPT's Vision capabilities allow it to recognize images, it can be utilized in the following way. The methods for using other sLLMs will be covered in Chapter 6.
Woman smiling, floral dress, flower garden, colorful flowers, bright weather, hands raised, joyful expression, outdoors.
Good Prompt
Combining the three prompts you've gathered so far can provide a richer and more detailed description.
1girl, solo, long_hair, breasts, looking_at_viewer, smile, open_mouth, brown_hair, dress, jewelry, flower, outdoors, teeth, necklace, white_dress, floral_print, realistic, Araffe woman in a floral dress standing in a field of flowers, woman standing in flower field, girl standing in flower field, girl standing in a flower field, girl frontal in a flower field, girl walking in flower field, woman in flowers, girl walking in a flower field, girl in a flower field, standing in a field with flowers, Woman smiling, floral dress, flower garden, colorful flowers, bright weather, hands raised, joyful expression, outdoors.
Is this prompt a good prompt? No.
Why? Because there are too many redundant or overlapping elements, making it chaotic.
And this is surprisingly common. Many prompts used by people are often cluttered like this.
1girl, 3d style, illustration style, girl, happy, smiling, red background, red clothing, girl, good quality, red and blue light, monotone, photo style, 1 shot, niji, good anatomy, 1girl, happy, white background
I won’t say things like writing prompts in the order of object, expression, composition, etc.
I simply recommend using clean prompts that anyone can visualize the same scene from when they hear the description.
Automation
Here's a small tip that could help expand your thinking. During the winter of 2023, we effectively used the IP-Adapter for a brand campaign. We placed around 100 images in folder 'a', which automatically triggered several workflows. For each image, we generated 20 new images. We ended up producing 2,000 images daily, and reviewing all of them took us about 30 minutes. From this, we selected around 20 images each day.
In this process, two things were adjusted: the weight of the IP-Adapter and the denoise value of the KSampler. Additionally, we automatically used the text obtained through CLIP. This approach not only assists in crafting prompts but also helps in creating programmatic workflows with nodes.